FlexiSpot の 一人がけの電動リクライニングソファ『Lotus Pro』を導入したら QoL が爆上がりした話
こんにちは。 青山(@amsy810)です。
みなさん、一人がけの電動リクライニングソファに座ったことってありますか? 買い物ついでに某家具店に行った時になんとなく座った一人がけの電動リクライニングソファの快適性にびっくりし、ここ数ヶ月密かに憧れてました。 最近のはとても進化していて、ほぼ寝れるレベルの快適性のものが多い気がします。 オフィスチェアでもCOFO ChairやFlexiSpot C7などリラックスできる体勢のものも増えてきていますね。
tl;dr
- FlexiSpot の一人がけの電動リクライニングソファは底面が100cm程度あり、ほぼ敷布団サイズの広さで快適
- type C対応・小物入れなどの過ごしやすさ、フットレスト・無段階調整・ロッキング機能などでリラックス度合いも抜群
- コスト的にも手を出しやすい範囲

FlexiSpotといえば昇降デスク
かれこれ5年以上FlexiSpotの昇降デスクにはお世話になっていて、エンジニア人生にとって今や欠かせないアイテムの一つになっています。 私の周りでも昇降デスクにして快適になってる人が多い印象です。 昇降デスクのメリットはスタンディングにできるだけではなく1cm単位で調整できるため、個人的には「コーディング用」「ミーティングや登壇用」「ご飯食べる用」など最適なサイズに合わせられるのも最高です。
FlexiSpotの電動リクライニングソファ
そんな私が、耐荷重が高いFlexiSpotのデスク製品群などを調べているときに目に止まったのが、FlexiSpotが出している電動リクライニングソファです。 そのFlexiSpotが電動リクライニングソファを出してるなんて気になりすぎる…と思ってました。
Flexispotって電動リクライニングソファまで出してたのか…Flexispotヘビーユーザーとしては気になり
— MasayaAoyama(青山真也) ⎈KubeCon Japan Co-Chair 6/16-17 (@amsy810) 2025年10月25日
引っ越すタイミングでE7Qにもするし、Flexispot率が上がりつつあるhttps://t.co/3EUqJWJR1R
なんと今回、FlexiSpot様からLotus Pro をご提供いただけることになり、とても良かったのでレビュー記事を書いております!(※ 一応PR記事という扱いになるのかもしれないです)
Lotus と Lotus Pro
Lotusの魅力はなんと言っても座面の大きさです! 実測で底面は約100cm、背面は90cm前後となっており、かなりゆったりと座れるためリラックス度が高いです。 布団の横幅が100cmなのを想像してもらえると、かなり広々していることがイメージできるかと思います! (カバーを外してないので真偽不明なのですが、)座面部分はチャックがついているので万が一汚しても洗えるのかなと思ってます。


Lotus シリーズは、蓮をイメージした椅子になっていて、ロッキング機能(ゆらゆらゆれる機能)や回転機能がついてます。 木製のロッキングチェアだと酔ってしまう私ですが、Lotusは重めの揺れだったので、私にとっては心地よい揺れ心地でした。 また、リクライニングしていくと先にフットレストだけが伸びるんですが、フットレストだけ伸ばした状態やリクライニングした状態にするとほぼ揺れなくなるため、揺れを止めた状態で使うこともできます。
また、ロッキング機能がついていることにより、前傾チルトとしても機能するため、意外と仕事用のチェアとしても十分使えそうです。


Lotus には*通常モデル(無印)と電動モデル(Pro)があります。電動の場合はtype CのUSBポートなども備え付けられていて、かつ無段階調整することができるのがメリットです。重量も3kg程度しか変わりません。 type Cポートがついているため、充電しながらくつろぐこともできます。

ついさっき気づいたんですが、しれっと収納まであるのでケーブル類や書籍などを入れておくこともできます。

搬入と設置
今回私は自分で設置してみたかったのでそうしましたが、ホームページを見る限り「搬入・設置組み立て無料」らしいので、置き場所さえあれば導入障壁はないと思います。 届いた段ボールは流石にでかい。


パーツは3つに分かれていてそれぞれそこまで重くはないので、男性なら一人でも設置は簡単でした。一応推奨は2人とのこと。

ケーブルのところもロック機構がついていたりと細かなところまで考えられていて良かったです。

背面は鉄じゃないのでそのまま置いても良さそうですが、「ラグの上に設置する」・「クッションフェルトを貼る」などした方が良さそうです。私はクッションフェルトを貼って動かしやすくしています。ラグ・サイドテーブルなどのオプションアイテムも売ってるので、興味がある方はこちらも一緒に頼むと良さそうです。

まとめ
予想以上にとても良かったので、お家環境をアップデートしたい方は検討してみても良いかもしれません : )

技術好きなあなたへ。メディア媒体の ThinkIT で記事を書いてみませんか?
TL;DR
- 技術記事をメディアで執筆したい方、募集中!
- ThinkIT(インプレス運営)で、あなたの技術的知見を発信するチャンス
- 書籍化の可能性もアリ。キャリアのステップアップに。
- フロントエンド・インフラ・AI などテーマは幅広く歓迎
- 連絡は Twitter(@amsy810)またはメール(amsy810@gmail.com)まで!
概要
「技術が好き」「深掘りした内容を誰かと共有したい」「アウトプットを通じてもっと成長したい」 そんな思いを持つエンジニアの方、いませんか?
技術メディア「ThinkIT」で連載記事を執筆したい方を探しています。
※私はインプレス社員ではなく、ThinkIT きっかけでキャリアが広がった一個人として記事を書いています。
執筆がもたらすキャリアの広がり
メディアでの執筆は、単なるアウトプットにとどまりません。
- ブログと同じく誰かのためになる
- メディア媒体の強みを活かして広く伝わる
- イベント登壇や書籍執筆など、次のチャンスにもつながる
実際、私自身もエンジニア2年目の頃に下記の連載をスタートし、数本公開したあとに書籍化を進めたこともあります。

ThinkITを運営するインプレスは出版事業も展開しており、テーマや内容によっては連載を土台にした書籍化に進めることもあります。
- 📘 impress top gear シリーズ
- → 最先端技術の解説書として書店にも並ぶ商業技術書
- 📗 技術の泉シリーズ
- → 技術同人誌的な自由なスタイルで出版できる電子書籍/オンデマンド印刷対応
どんな人が対象?
- 学んだ技術や構築した仕組みを言語化して整理したい方
- 「誰かの役に立つ記事を書いてみたい」と思ったことがある方
- 発信力を強みにしたい、キャリアの幅を広げたい方
若手・中堅問わず、技術に熱意がある方なら誰でも歓迎です!
執筆スタイル・進め方のイメージ
- 連載の場合のペースは月0.5~2本程度(無理のない頻度でOK)
- 単発の執筆ももちろん OK です
- Google Docs や Markdown で執筆、編集サポートもあり
- 執筆料も支給されるので、デスク周りの強化・エンジニアリングの効率化にも使えます!
一人での連載はもちろん、 会社メンバーで持ち回り執筆、 コミュニティでの共同連載など、自由な形で参加できます。
テーマについては過去の連載などを見てみるとイメージがより湧くかもしれません。 最近だと、下記あたりの連載などに関わっていました。
 (個人で全5回で連載)
TypeScriptでCLIを作って学ぶAST 記事一覧 | Think IT(シンクイット)
(個人で全5回で連載)
TypeScriptでCLIを作って学ぶAST 記事一覧 | Think IT(シンクイット)
 (会社で持ち回り執筆)
Kubernetesスペシャリストが注目する関連ツール探求 記事一覧 | Think IT(シンクイット)
(会社で持ち回り執筆)
Kubernetesスペシャリストが注目する関連ツール探求 記事一覧 | Think IT(シンクイット)
⸻
興味が湧いたら「ちょっと話を聞いてみたい」くらいでも全然OKです!お気軽にご連絡ください。
マルチテナント/クラスタ向け Kubernetes Workspace の実装 2024
はじめに
体感でここ1-2年、Kubernetes に Workspace という概念を導入し、マルチテナント環境を構成する方法が模索されています。 今回は KubeCon + CloudNativeCon NA 2024 で紹介されていた、Kubernetes の Workspace(マルチテナント機能) に関する実装を 2 つほど紹介したいと思います。概要の紹介に留めるため、詳細については各セッションを確認してください。 ※なお、ここで紹介していないマルチテナント Kubernetes に関する技術は他にもたくさん(Open Cluster Management、vCluster、e.g.)あります。
- Kubernetes API の前段に Proxy を配置することによる Workspace の実現
- kcp-dev/kcp を用いた Workspace の実現
1. Kubernetes API の前段に Proxy を配置することによる Workspace の実現
Kubernetes に対して、複数の Namespace を束ねた Workspace という概念を導入し、クラスタをマルチテナント利用ができるようにする方法です。 Workspaceの概念を導入すると、Cluster-scoped/Workspace-scoped/Namespace-scopedの3種類の階層となるため、あるユーザーが従来の「(クラスタ上の)全てのリソースの一覧を取得する」リクエストを送った場合には、該当Workspaceに合致するリソース一覧が取得される形になります。 そのため、単一のクラスタ上でNamespaceも利用可能な複数のテナントを払い出すことができるようになります。
実現方法としては、Kubernetes APIの全台にProxyサーバーを配置し、リクエストを中継する際に適切なSelectorを配置することで環境の分離を行います。
例えば、下記の図では my-workspace には Namespace a、b、c が含まれているため、 my-workspace の全ての Namespace 上の Pod の list リクエスト(ユーザーからすると kubectl get pods -A)を行うと、後段の kube-apiserver に対するリクエストを行う際には Namespace に対する Selector が設定された状態でリクエストが行われます。これらの処理を実現するために、field selector での In/NotIn などの operator が利用できるようにする修正 #128154 などが検討されています。
この Proxy パターンの良いところとしては、HTTPリクエストをシンプルに書き換える構成であること、kube-apiserverやetcdに対する実装の変更の必要はないため高コストなencoding/decodingなどの処理が必要ないことが挙げられています。

また、 my-workspace Workspace を使っているユーザーが workspace-scoped なリソースを作成する場合には、現在は特定のNamespaceにリソースを作成することで擬似的に実現しています。(Kubernetes 自体が Workspace 自体をネイティブにサポートしているわけではないため。実際にCluster-scopeなリソースを作成しない。)

また、認証ついては Proxy では行わず、ExtraInfo として Workspace の情報を持った状態でkube-apiserver 側に処理を委譲します。そのため、Proxy 側はシンプルな状態を保ちます。 実際に認証処理を行う kube-apiserver 側では、Workspace 用に実装された Authorization Plugin を利用して認証処理を行います。そのため、kube-apiserver 側のオプションを変更する必要があります。
詳細については、Kubernetes Workspaces: Enhancing Multi-Tenancy with Intelligent Apiserver Proxying - James Munnelly & Andrea Tosatto, Apple のセッションを確認してください。
2. kcp-dev/kcp を用いた Workspace の実現
Kubernetes のコントロールプレーンの仕組みを汎用的に利用できるようにする kcp-dev/kcp プロジェクトがあります。kcp にはPodやDeploymentなどのAPIリソースは存在せず、軽量なコントロールプレーンの部分のみを提供します。kcpではこのコントロールプレーンの部分のみを用いて、Kubernetesライクな形でシステムを管理する手段や、マルチクラスタ/テナント向けの仕組みを実現することを目指しています。なお、合わせて KEP-4080 で kube-apiserver のコア部分に関してはgeneric control planeとしてパッケージが分離され、再利用しやすい形になっています。
kcpではetcdとgeneric control planeを利用して、単一etcd上に複数のcontrol plane(logical cluster)を構築します。つまり、複数のkube-apiserver相当の仕組みを単一クラスタ上で実現することができます(≒単一のシステム上で軽量なkube-apiserverを大量に立てることができる)。

このkcpでも workspace の概念が実現されています。仕組みとしては、Linux の directory/file と同じような概念を導入し、directoryがfileへのエントリを持てるのと同じように階層化された構造にlogical clusterを紐づけるような形となっています。

kcpも前述の Proxy を使った実装と同じように、パスベースでクラスタのエンドポイントが払い出されるような形になっています。

kcpでは、Linux がファイルシステムに対してボリュームをマウントできるのと同じように、この仕組みを利用して外部のクラスタを特定のworkspaceにマウントする機能なども提供されています。

kcpでは他にもcontroller-runtimeを拡張した複数のコントロールプレーン(マルチクラスタ)に対するコントローラーの例が公開されています。弊社でも複数のKubernetes Clusterに対するコントローラーなどが存在しているため、マルチクラスタ向けの拡張がcontroller-runtimeに導入されるきっかけになればと思い期待しています。
詳細については、Deep Dive Into Generic Control Planes and Kcp - Stefan Schimanski, Upbound & Mangirdas Judeikis, Cast AI のセッションを確認してください。
まとめ
Kubernetes Workspace を使いたいケースは、Kubernetes ベースにした Platform やサービスを提供するケースやマルチクラスタ・マルチクラウド/ハイブリッドクラウドなど、そこまで多くはないかもしれません。一方でそうしたシステムを実装する際には、柔軟に管理する手法として検討してみるのも良さそうです。 また、kcpに関しては発表直後から個人的にはKubernetes 2.0や将来的な影響も大きいプロジェクトだと思っており、継続して追っています。今回の発表ではcontroller-runtimeに対するProgramming Modelの提案なども行われており、より将来に期待しています。
Gateway API の現在地 〜これまでとこれから〜
この記事は Kubernetes Advent Calendar 2023 の 1 日目の記事です。
こんにちは。サイバーエージェントの青山(@amsy810)です。
2017 年から 12/1 の初日に記事を書き始め、早いもので 7 年目になりました。
2020/2021 年の、おうち Kubernetes のために Synology CSI に追加実装をしたりした話もネタとして面白いのでぜひ見てみてください。
今年は約 1 ヶ月前に GA した Gateway API の現在地、将来的に Gateway API がどう発展していきそうかについてお話ししたいと思います。

Gateway API の GA Release
Gateway API はこの記事執筆時点 12/1 の約一ヶ月前の 2023/10/31 に v1.0.0 で GA リリースされました。
GKE を利用しているユーザーは、もっと前に GA していたはずと思った方もいらっしゃるかもしれませんが、GA したものが異なります。 GKE では Gateway API をサポートする GKE Gateway Controller が提供されており、GKE Gateway Controller 自体は、API の GA よりもいち早く 2022/11 に GA しています。
今回 GA したのは Gateway API(Gateway / HTTPRoute / etc などのリソース)の方で、これにより基本的な仕様は大まかに固まったということになります。
Gateway API とは?
Gateway API では、Ingress で生じていた課題を解決することができるようになっています。 例えば、インフラ提供者・クラスタ運用者・アプリケーション開発者のそれぞれで、Ingress で設定を行いたい責務が異なります。Ingress ではクラスタ運用者とアプリケーション開発者の関心事に対する設定を単一の Ingress リソースで行っていましたが、Gateway API では Gateway・XXXRoute(HTTPRoute や TCPRoute)の複数のリソースで設定を行います。また、Namespace を跨いだ委譲なども可能な仕組みになっています。
- インフラ提供者
- 利用可能な Gateway 実装の設定(インストール)
- クラスタ運用者
- アプリケーション開発者
- パスベースのルーティング設定(特定のパス > 特定の Service)
- 加重ルーティングの設定
ここでは Gateway API の詳細については詳しくは説明しませんが、興味のある方は公式サイトのIntroductionを読んでみてください。
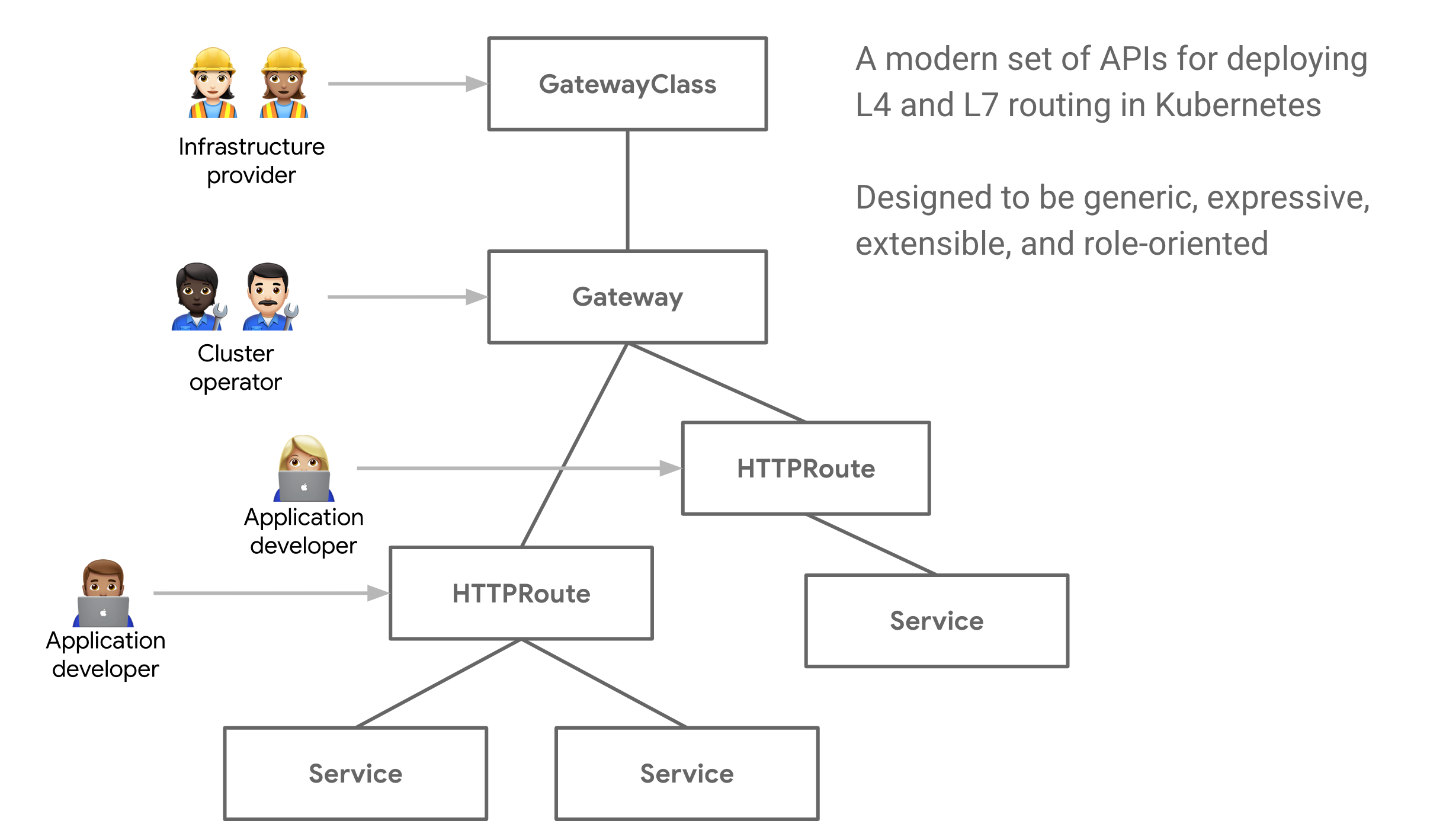
Gateway API のこれまでの歩み
Ingress に生じていた課題の精査、Gateway API が Ingress v2 として設計が始まった背景、そして現在の Gateway API の設計に至るまでの経緯については、KubeCon + CloudNativeCon NA 2023 の「Gateway API: The Most Collaborative API in Kubernetes History Is GA - Rob Scott, Google & Nick Young, Isovalent」でもまとめられているので、Gateway API の 4 年の Upstream の歴史について興味のある方は見てみると楽しめると思います。
なお、最初期は Ingress v2 として始まった Gateway API プロジェクトですが、Ingress 自体は今後も利用可能で、非推奨にする計画は現時点ではありません。Ingress は HTTP エンドポイントを公開するシンプルな仕組みとして残り続け、Gateway API は汎用的で高機能な仕組みとして提供される予定です。これは KubeCon などでも幾度となくメッセージとして伝えられていたものなので、現時点での信憑性はかなり高いものでしょう。
現時点で Gateway API に対応している実装
Gateway API が利用できる環境は公式サイトで公開されており、記事執筆時点でもかなり多くの実装が行われています。 パブリッククラウド環境の場合は、GKE は GA ステータスとなっていますが、EKS や AKS は preview や alpha ステータスとなっているため、利用には注意が必要です。
オンプレミス環境やパブリッククラウドにセルフデプロイする場合の選択肢としては、「Contour(beta)」「Envoy Gateway(beta)」「Cilium(beta)」などが適しています。Cilium は CNI Plugin のため、別の CNI Plugin を利用している Kubernetes クラスタでは追加でインストールして利用することなどもできないため注意してください。
また、Gateway API は、Service Mesh でも利用できるようになっています。Service Mesh における Gateway API 実装は、GAMMA (Gateway API for Mesh Management and Administration) initiative によって進められており、 v0.8.0 の時点で Experimental なステータスです。 そのため、やや Too much な構成としてはサービスメッシュ実装でもある「Istio(beta)」も選択肢としては挙げられます。
一方で、Ingress 実装として最もメジャーとも言える「ingress-nginx」の Gateway API 対応はされないのでしょうか?
ingress-nginx の Gateway API 対応について
kubernetes/ingress-nginx の Gateway API については、2021年ごろに Issue #7517 が建てられ始め、Gateway API の仕様成熟に伴い、実装に向かっています。
kubernetes/gateway-nginx のように新しいリポジトリで新しいものを実装するのではなく、同一リポジトリで両サポートする方向で実装が進められているため、将来的にはバージョンアップすることでIngressとGateway APIの両方が利用できるようになっていきそうです。
また、先日のKubeConであった「What's Happening with Ingress-Nginx! - James Strong, Chainguard & Ricardo Katz, VMware」のセッションでも、2024 年の計画として Gateway API への対応について言及されています。 Issueやセッションを見るとわかるのですが、ingress-nginxプロジェクトでは現在 Gateway API 実装の前段として、大幅な実装変更の前に優先度の高い「利用されていない機能の削除・リファクタリング」・セキュリティ対策のための「Controlplane(Kubernetes Controller) と Dataplane(Nginx)の分離」などが進められています。そのため、Gateway API 対応の実装が少し遅くなっている状況のようです。
Gateway API に関する機能強化 Gateway Enhancement Proposals(GEPs)
Gateway API に関する機能強化は、Gateway Enhancement Proposals(GEPs)によって管理されています。 Kubernetes に対する機能強化提案 Kubernetes Enhancement Proposals(KEPs)と類似したフローで管理されています。

将来的に追加が検討されている Experimental な GEPs には、下記のようなものが存在します。Experimental ステータスな GEPs はいくつかの実装がすでに用意されていることもあります。
- GEP-1016(Status = Experimental)
- GRPCRoute の追加
- GEP-1651(Status = Provisional)
- GEP-1742(Status = Experimental)
- HTTPRoute での timeout 設定の追加
- GEP-1867(Status = Experimental)
- GEP-2162(Status = Experimental)
- Gateway Controller がサポートしている機能セットを GatewayClass で列挙可能にする
Service の Gateway API への統合案
Kubernetes の共同創設者であり、現在もコアメンテナーを務める Tim Hockin 氏が KubeCon + CloudNativeCon NA 2023 で講演した LT 「Lightning Talk: Why Service Is the Worst API in Kubernetes, & What We’re Doing About It」では、Service リソースの問題点と、Gateway API を利用した変更案を紹介していました。 現状の Service リソースはさまざまな拡張が行われた結果、非常に多くの機能を持っており、かつ重要なコア API のため影響度が高く、改修が困難な状況になってしまっています。 Tim のこのセッションでは、Service を Pod をひとまとめにする抽象的な概念にする部分のみに機能を絞り、ClusterIP や LoadBalancer などの Pod に対する接続性を用意する部分は Gateway API で担うといった変更案をアイデアとして語られています。
Kubernetes を初めて触った時に、Service と Ingress や Service と Gateway API をみて、ロードバランサーを制御する API が 2 通りあり違和感を感じた方もいらっしゃるかと思います。 この改修が入ることによって、Service は Pod を抽象的にまとめるもの・Gateway API は接続性を担うものと責務の分離がされるとよりわかりやすいと感じる方もいるかと思います。
今回のセッションではいちアイデアとして語られていただけなので今後の方向性が確定しているわけではありませんが、Gateway API を通じて、また数年かけて最古の API の一つである Service の改修が進んでいくことも楽しみです。

まとめと今後
弊社ではプライベートクラウド上に独自の Kubernetes as a Service の AKE を提供しており、独自の Ingress Cont¥roller や Cloud Controller Manager を実装しています。そして Gateway API の GA に伴い、じきに Gateway Controller の実装も検討しています。今後は上記のような実装に関わりそうな GEPs のフィールド変更などを適切にウォッチしていくため、続報や実装時にはまた改めてブログにでもまとめさせていただきます。 なお、こうした仕事にご興味がある方がいらっしゃれば、ぜひ採用サイトを覗いてみてください。

参考: Gateway API 関連の便利ツール
OpenClarity プロジェクトの KubeClarity で始めるお手軽 SBOM/脆弱性管理
OpenClarity プロジェクトと KubeClarity を用いた SBOM 管理
この記事は Kubernetes Advent Calendar 2022 の 2 日目の記事です。
こんにちは。 サイバーエージェント CIU(CyberAgent group Infrastructure Unit)で KaaS 基盤のプロダクトオーナーを務めている青山です。 採用もしているので、ご興味のある方はぜひ Twitter DM などいただければと思います。
今回の Advent Calendar は、去年の KubeCon で印象に残っていた APIClarity の兄弟プロダクトである、KubeClarity について紹介しようと思います。 (2020/2021 に引き続きおうちKubernetesでCSIガチネタしたかったのですが、時間が取れず…)
APIClarity との出会い
APIClarity は API リクエストをキャプチャ・分析し、OpenAPI Schema の再生成・Zombie API の検知・Shadow API の検知などを行うプロダクトです。これにより、潜在的なリスクを特定したり、Observability の手助けをすることができます。
去年参加した KubeCon + CloudNativeCon NA 2021で知り、アーキテクチャが面白かったので記憶に残っていました。
APIClarityでは、Istio で構成されたサービスメッシュ上の各 Envoy Proxy 内で、Proxy-WASM を利用して実装された WASM のプログラムを動作させ、APIリクエストを収集します。
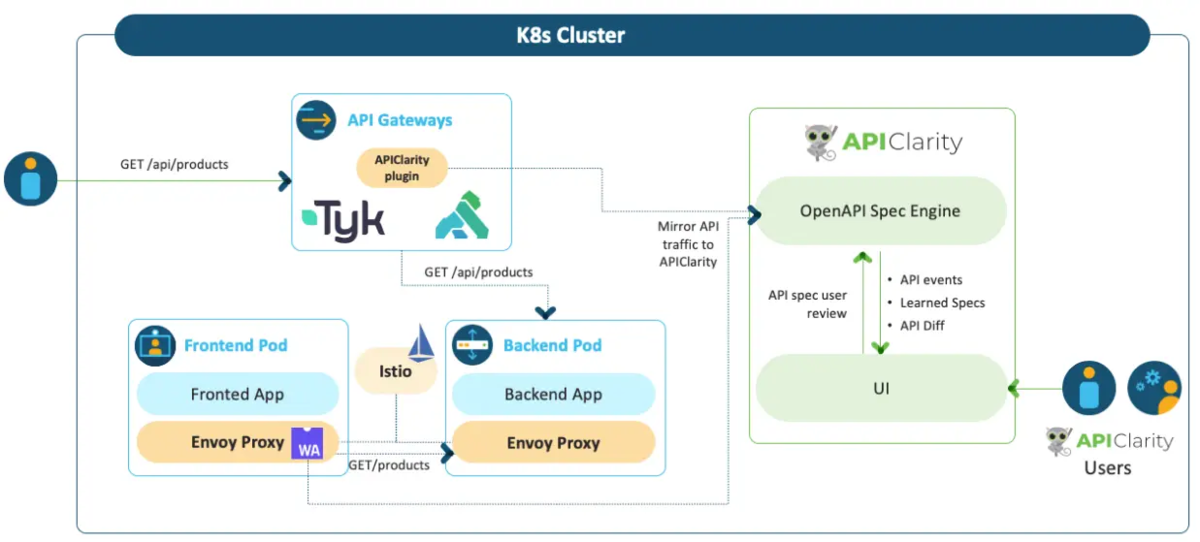
APIClarity について興味がある方は、詳細について下記を参照してみてください。
ebpfとWASMに思いを馳せる2022 / techfeed-conference-2022-ebpf-wasm-amsy810 - Speaker Deck
OpenClarity プロジェクト
OpenClarity は、セキュリティや Observability のための OSS ツール群を開発するプロジェクトです。 APIClarity も OpenClarity プロジェクトが公開するプロダクトの一つです。 Cisco がリードしています。
今年の KubeCon + CloudNativeCon NA 2022 では、(おそらくスポンサーの)Keynote で OpenClarity について紹介されていました。
現段階では下記の 3 種類のプロダクトが公開されています。
- APIClarity
- KubeClarity
- FunctionClarity

KubeClarity
今回紹介する KubeClarity は下記の 3 つのことを実施することができます。 また、現状内部で利用されているスキャナー類は Syft/Grype/Dockle ですが、別のプロダクトの利用も視野に入れているようです。
- SBOM(Software Bill Of Materials)の生成
- Content Analyzer: Syft
- 脆弱性スキャン
- Vulnerability Scanner: Grype
- CIS Docker Benchmark のテスト
- Banchmarker: Dockle
コンテナイメージのスキャン
コンテナイメージのスキャン・解析はクラスタ上で実行されているイメージ単位で Job リソースが作成されて実施されます。 Job リソースが作成されると、内部では下記の2つの Scanner が動作します。 Syft/Grype/Dockle はそれぞれ Go の SDK が提供されているため、それを用いてスキャン・解析を行っています。
- https://github.com/openclarity/kubeclarity/blob/7f3d166ad4feb0bda93138e6c4e4fe12b6c360a5/runtime_k8s_scanner/pkg/scanner/scanner.go#L71
- https://github.com/openclarity/kubeclarity/blob/7f3d166ad4feb0bda93138e6c4e4fe12b6c360a5/cis_docker_benchmark_scanner/pkg/scanner/run.go#L74
現状デプロイされるJobは実際にコンテナイメージを持っているノードに明示的にスケジューリングし、そのノード上のイメージを利用するなどは行っていません。 クラスタ上にデプロイされているイメージを再利用したスキャンの仕組みを実装することは以前から考えていたので、そのあたりの機能がKubeClarityにも入ると良さそうだなと考えています。

Syft と Grype による脆弱性スキャンの高速化
Syft はコンテナイメージ単位でインストールされたパッケージ類のリストである SBOM を生成します。 Grype は Syft が生成した SBOM を用いて脆弱性の有無を検査することができるため、再度コンテナイメージをスキャンするのと比較して、高速に脆弱性スキャンを実施することが可能です。
実際に runtime_k8s_scanner の実行部分を確認すると、SBOM DB からデータの取得を試み、結果を利用しています。
KubeClarity におけるデータ
KubeClarity では、データを 4 つに分類して管理しています。
- Application: 実行されているPod(実際にはDeploymentなどの粒度)
- Application Resource: コンテナイメージ
- Package: 利用しているパッケージ(rpm や deb などの OS 系 / npm や gomod などの言語系)
- Vulnerability: 脆弱性情報

WebUI
Web UI は使いやすく作られており、脆弱性対応のはじめの一歩や簡易的に実現する手段としても重宝できそうです。
UI からは Pod・コンテナイメージ・パッケージ・脆弱性情報(CVE)それぞれの情報で検索をかけることが可能になっています。 運用を考えた際生じる、下記のようなオペレーションが可能です。
- 特定の CVE に紐づくコンテナイメージの一覧を取得
- 特定のバージョン以下のパッケージを利用しているコンテナイメージ一覧を取得
- 特定の CVE に紐づく Pod 一覧(現在クラスタで起動しているもの)を取得
- 特定のパッケージを利用している Pod 一覧(現在クラスタで起動しているもの)を取得
KubeClarityの導入は非常に簡単かつ環境に影響を与えないため、一度クラスタにデプロイしてスキャンを実施し、
などを行って、定期的に単発で対応するといったことにも可能です。

また、特定の脆弱性が出たタイミングで導入してスキャンし、一覧を習得した上で、特定の脆弱性を持ってしまっているDeploymentを洗い出すといったことにも利用可能です。

もちろん CVE に関する情報も確認することができます。


SBOM の情報と紐付けて、それらのパッケージがどの程度実行しているPodから使われているか、コンテナイメージに含んでいるかなどを確認することもできます。

Dockle も有効にしてスキャンしている場合には、Dockerfile で修正したほうが良い箇所も確認できます。

他にも、様々な形で情報を表示することが可能です。


まとめ
今回は比較的用意に SBOM や脆弱性管理を行うことができる KubeClarity について紹介しました。 OpenClarity Project では、あったら嬉しいプロダクト開発がされている印象なので、今後もウォッチしていきたいですね。
ちなみに 3-shake さんのイベントでこのあたりをデモ付きで紹介する予定なので、よければご参加ください :)
おうち Kubernetes に最適な Synology 公式の CSI Driver がリリースされた話と Cloning / Snapshot feature deep dive
こんにちは。青山(@amsy810)です。
この記事は、Kubernetes Advent Calendar 2021 の 1日目の記事です。
いよいよ今年もアドベントカレンダーの季節が始まりました。今年も1ヶ月間わいわいしていきましょう!
Agenda
おうち Kubernetes
今回はかわいい下駄箱 DC に佇む、箱物ストレージの Synology に新たな CSI Driver を適用していきます。

去年の jparklab/synology-csi CSI Driver に機能実装した話
去年はおうちKubernetes向けのストレージを Synology に刷新したのもあって、jparklab/synology-csi という有志によって作られた 非公式の Synology CSI Driverに対して、PVCとファイルシステムの動的なリサイズを行う VolumeExpansion の機能を実装しつつ、様々な CSI Driver での内部実装の紹介する話をしました。
- CSIではどうやってブロックデバイスの拡張を検知しているか
- CSIではどうやってファイルシステムもPod再起動なしに動的に拡張されているか
- Controller PluginとNode Pluginの役割分担
といった詳細な話が気になる方は、ぜひ去年のも見てみてください。
また、CSI とは何かといった話や、CSI Driver の大枠の仕組みについては去年の記事を見てみてください。
Synology 公式の CSI Driver
今年は VolumeSnapshot あたりを実装しつつ、内部実装を紹介する話でもしようかなぁと思っていました。 しかし、2021-08-31 に Synology 公式 の CSI Driver(SynologyOpenSource/synology-csi)がリリースされていました。しかも Cloning や Snapshot featureにも対応。
そこで今回は公式の Synology CSI Driver について紹介しようかと思います。
SynologyOpenSource/synology-csi の概要
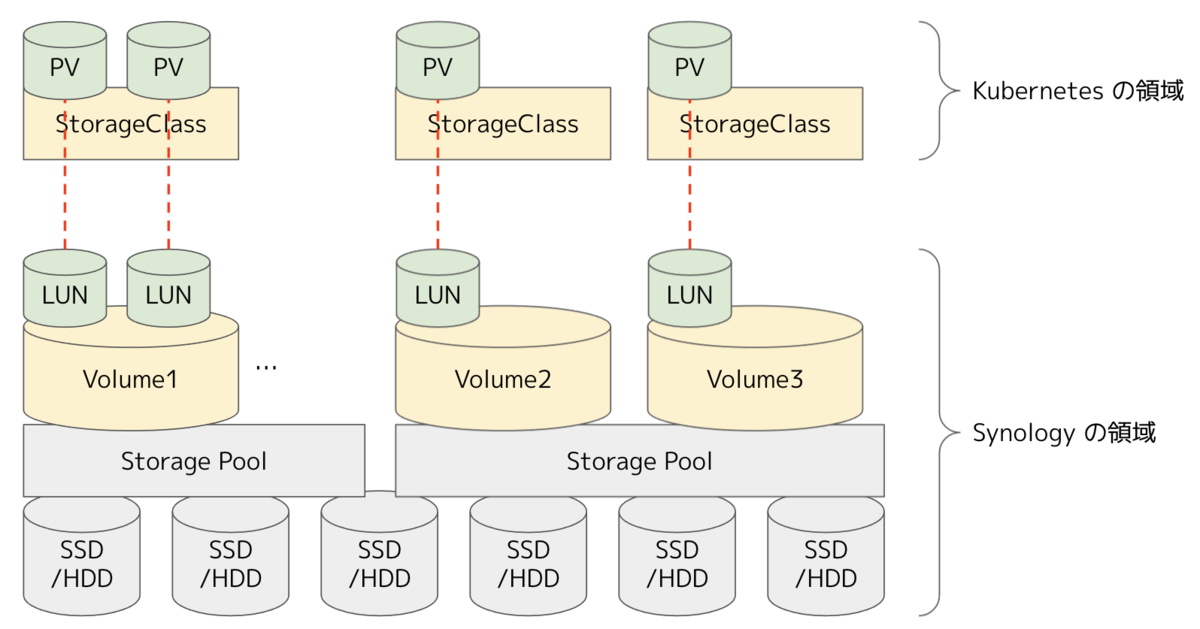
公式の Synology CSI Driver では、事前に NAS 側に複数の HDD/SSD を束ねたストレージプールを定義し、Synology Volume を作成しておきます。 StorageClass は Synology Volume 単位で定義できるようになっているため、HDDとSSD混在環境であれば、一つの筐体でも性能差のある複数の StorageClass を提供することができます。
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: synology-iscsi-storage parameters: location: '/volume1' fsType: 'ext4' dsm: 'xxx.xxx.xxx.xxx' reclaimPolicy: Delete
その後、StorageClass を利用して Dynamic Provisioning されると、PV の単位で LUN が払い出されていきます。 そして、払い出された LUN は iSCSI 経由でアタッチされ、ReadWriteOnceな状態で利用していきます。
Requirements 周りの話
DSM の Requirements
Synology の NAS には、DSM(DiskStation Manager)というオペレーティングシステム(兼 API)が搭載されています。 公式の SynologyOpenSource/synology-csi を利用するには、2021年7月ごろにリリース されたDSM 7.0系以降が必要です。
Kubernetes の Requirements と v1.22 への対応
また、公式にサポートがアナウンスされている Kubernetes version は v1.19 までになっています。 私の Kubernetes 環境は最新の v1.22 ですが、下記の対応をすることで v1.22 でも動作確認済みです。
CSI attacher(external-attacher)が v2.1 系で古いため、VolumeAttachment リソースの API Version が存在しない v1beta1 を参照している
I1125 17:11:55.649047 1 reflector.go:188] Listing and watching *v1beta1.VolumeAttachment from k8s.io/client-go/informers/factory.go:135 E1125 17:11:55.650747 1 reflector.go:156] k8s.io/client-go/informers/factory.go:135: Failed to list *v1beta1.VolumeAttachment: the server could not find the requested resource
=> 対応: CSI attacher のバージョンを上げる(v2.1.0 > v3.3.0)
CSI attacher v3.x 系から attach を行う reconcile 時にも volumeattachment/status patch リクエストが送られるようになり、権限不足でエラーを返す
I1125 17:19:16.077875 1 controller.go:208] Started VA processing "csi-daee6d88cfec18e000fbc38dfa5326a180e73dd47bf62a63eca30a435852cdae" I1125 17:19:16.077894 1 trivial_handler.go:53] Trivial sync[csi-daee6d88cfec18e000fbc38dfa5326a180e73dd47bf62a63eca30a435852cdae] started I1125 17:19:16.077914 1 util.go:38] Marking as attached "csi-daee6d88cfec18e000fbc38dfa5326a180e73dd47bf62a63eca30a435852cdae" W1125 17:19:16.083865 1 trivial_handler.go:57] Error saving VolumeAttachment csi-daee6d88cfec18e000fbc38dfa5326a180e73dd47bf62a63eca30a435852cdae as attached: volumeattachments.storage.k8s.io "csi-daee6d88cfec18e000fbc38dfa5326a180e73dd47bf62a63eca30a435852cdae" is forbidden: User "system:serviceaccount: synology-csi:csi-controller-sa" cannot patch resource "volumeattachments/status" in API group "storage.k8s.io" at the cluster scope
=> 対応: volumeattachment/status への RBAC の権限を追加する
※ Status フィールド自体は v1beta1 からももともと利用されていたため、そもそもvolumeattachment/status への権限は必要そう。PR も出されているのでいずれ修正予定。
# kustomization.yaml patches: - ./patches.yaml patchesJson6902: - target: group: rbac.authorization.k8s.io version: v1 kind: ClusterRole name: synology-csi-controller-role patch: |- - op: add path: /rules/0 value: {"apiGroups": ["storage.k8s.io"], "resources": ["volumeattachments/status"], "verbs": ["get", "list", "watch", "update", "patch"]}
# ./patches.yaml apiVersion: apps/v1 kind: StatefulSet metadata: name: synology-csi-controller namespace: synology-csi spec: template: spec: containers: - name: csi-attacher image: k8s.gcr.io/sig-storage/csi-attacher:v3.3.0
Volume の Cloning と Snapshot
SynologyOpenSource/synology-csi では、Cloning と Snapshot をサポートしています。
PVC 作成時に spec.dataSource に複製元 PVC を指定して、複製元の PVC をクローンして PVC 作成する
kind: PersistentVolumeClaim spec: dataSource: kind: PersistentVolumeClaim name: sample-pvc-dynamic
PVC 作成時に spec.dataSource に Snapshot リソースを指定して、PVCを作成する
kind: VolumeSnapshot metadata: name: sample-volumesnapshot spec: source: persistentVolumeClaimName: sample-pvc --- kind: PersistentVolumeClaim metadata: name: sample-pvc-restored spec: dataSource: kind: VolumeSnapshot name: sample-volumesnapshot
今回はせっかくなので SynologyOpenSource/synology-csi を例に、CSI Driver の Cloning と Snapshot の実装を少し深ぼって紹介したいと思います。
Cloning の実装
Cloning の場合、PVCに指定された spec.dataSource の PVC の情報を元に、新たな PVC を作成します。 そのため、CSI Driver の Controller Plugin 側の CreateVolume() 関数に手を加えて実装していきます。 例えば SynologyOpenSource/synology-csi では、spec.dataSource に PVC が指定されていた場合には、その PVC の LUN を元に PV を生成するようになっています。
func (cs *controllerServer) CreateVolume(ctx context.Context, req *csi.CreateVolumeRequest) (*csi.CreateVolumeResponse, error) { ...(省略)... if volContentSrc != nil { if srcVolume := volContentSrc.GetVolume(); srcVolume != nil { srcVolumeId = srcVolume.VolumeId } else { return nil, status.Errorf(codes.InvalidArgument, "Invalid volume content source") } } ...(省略)... spec := &models.CreateK8sVolumeSpec{ ...(省略)... SourceVolumeId: srcVolumeId, } lunInfo, dsmIp, err := cs.dsmService.CreateVolume(spec) ...(省略)... } func (service *DsmService) CreateVolume(spec *models.CreateK8sVolumeSpec) (webapi.LunInfo, string, error) { if spec.SourceVolumeId != "" { /* Create volume by exists volume (Clone) */ k8sVolume := service.GetVolume(spec.SourceVolumeId) if k8sVolume == nil { return webapi.LunInfo{}, "", status.Errorf(codes.NotFound, fmt.Sprintf("No such volume id: %s", spec.SourceVolumeId)) } dsm, err := service.GetDsm(k8sVolume.DsmIp) if err != nil { return webapi.LunInfo{}, "", status.Errorf(codes.Internal, fmt.Sprintf("Failed to get DSM[%s]", k8sVolume.DsmIp)) } lunInfo, err := service.createVolumeByVolume(dsm, spec, k8sVolume.Lun) return lunInfo, dsm.Ip, err } ...(省略)... }
synology-csi/controllerserver.go at release-v1.0.0 · SynologyOpenSource/synology-csi · GitHub
synology-csi/dsm.go at release-v1.0.0 · SynologyOpenSource/synology-csi · GitHub
Snapshot の実装
Snapshot の実装は、大きく分けて Snapshot と Restore の 2 つのパートに分かれています。
Snapshot
VolumeSnapshot リソースでスナップショットを管理する機能を実装するには、CSI Driver の Controller Plugin 側に CreateSnapshot()・DeleteSnapshot()・ListSnapshot() の 3 つの関数を実装する必要があります。ストレージバックエンド側でボリュームやスナップショットを生成すればよいため、Node Plugin 側の実装はありません。
例えば SynologyOpenSource/synology-csi では、CreateSnapshot()関数で VolumeSnapshotリソースに指定されている PVC の情報を元に、LUNに対してスナップショットを生成しています。
synology-csi/controllerserver.go at release-v1.0.0 · SynologyOpenSource/synology-csi · GitHub
Restore
Restore 部分は、Cloning と同様に spec.volumeSource に Snapshot が指定された場合の処理を実装することを意味します。 そのため、CSI Driver の Controller Plugin 側の CreateVolume 関数に手を加えていきます。 例えば SynologyOpenSource/synology-csi では、spec.dataSource に VolumeSnapshot リソースが指定されていた場合には、その VolumeSnapshot が紐付いているスナップショットを元に PV を生成するようになっています。
func (cs *controllerServer) CreateVolume(ctx context.Context, req *csi.CreateVolumeRequest) (*csi.CreateVolumeResponse, error) { ...(省略)... if volContentSrc != nil { if srcSnapshot := volContentSrc.GetSnapshot(); srcSnapshot != nil { srcSnapshotId = srcSnapshot.SnapshotId } else if srcVolume := volContentSrc.GetVolume(); srcVolume != nil { srcVolumeId = srcVolume.VolumeId } else { return nil, status.Errorf(codes.InvalidArgument, "Invalid volume content source") } } ...(省略)... spec := &models.CreateK8sVolumeSpec{ ...(省略)... SourceSnapshotId: srcSnapshotId, SourceVolumeId: srcVolumeId, } lunInfo, dsmIp, err := cs.dsmService.CreateVolume(spec) ...(省略)... } func (service *DsmService) CreateVolume(spec *models.CreateK8sVolumeSpec) (webapi.LunInfo, string, error) { if spec.SourceSnapshotId != "" { /* Create volume by snapshot */ for _, dsm := range service.dsms { snapshotInfo, err := dsm.SnapshotGet(spec.SourceSnapshotId) if err != nil { continue } lunInfo, err := service.createVolumeBySnapshot(dsm, spec, snapshotInfo) return lunInfo, dsm.Ip, err } return webapi.LunInfo{}, "", status.Errorf(codes.NotFound, fmt.Sprintf("No such snapshot id: %s", spec.SourceSnapshotId)) } ...(省略)... }
synology-csi/controllerserver.go at release-v1.0.0 · SynologyOpenSource/synology-csi · GitHub
synology-csi/dsm.go at release-v1.0.0 · SynologyOpenSource/synology-csi · GitHub
実装関連の参考情報
Controller Server
Node Server
Future work
今回公開された Synology CSI Driver でサポートしているのは SAN 向けの機能です。 NetApp Trident のように ReadWriteMany 向けの Dynamic Provisioning も Synology の Shared folder の機能を使いつつ実装できると、更にユースケースが広がりそうですね。
ソースコードを見てる範囲では、Shared folder 用の DSM API を操作する関数は用意されているが使われていない状態だったので、将来的にはサポートされるかもしれません。 12月に手が空けば、実装しつつ、別日のアドベントカレンダーでも書こうかと思います。
まとめ
あんまり特出して書くことがない程度には完成度が高い状態でした。 Synology CSI Driver を利用することで、箱物ストレージを簡単に得ることができるのでロマンがあります。
また、Stateful なアプリケーションを Kubernetes で運用していく場合、Snapshot の CSI Features を利用したくなったり、エコシステムによってはこの機能自体が必要なケースも出てくるかと思います。その点では、今回公開された公式の Synology CSI Driver は多くの機能がサポートされているため、検証用途にはとても十分です。
余談ですが、Synology の公式サイトには、「個人向け」「中小企業向け」以外にも、「IT 愛好家」向けの項目があって好感が持てます。いわゆる 逸般の誤家庭 向けってやつですね。
逸般の誤家庭 な皆さん、年末年始は Synology CSI Driver を整備して、ぜひ楽しんでみてはいかがでしょうか。
以上、青山(@amsy810)からでした〜
おうち Kubernetes 向けに Synology CSI Driver に VolumeExpansion を実装した話
こんにちは。 青山(amsy810 )です。
この記事は Kubernetes Advent Calendar の 1 日目の記事です。
いよいよアドベントカレンダーが始まりましたね。1か月間わいわいしていきましょう!
どこかの誰かに実装系の記事のほうが面白いよねってフリをされたので、今年は Synology CSI Driver に VolumeExpansion を実装しつつ、内部実装の紹介 をします。 VolumeExpansion は 1日あれば実装が終わるくらいの規模感でした。
おうち Kubernetes
みなさんのおうちの Kubernetes はどこにありますか? ちなみに私は下駄箱にあります。下駄箱DC。上流スイッチもここに集約されています。
そして皆さんストレージはどうしてますか? hostPath や Local PV で我慢してる人がいたり、Longhorn や Rook/Ceph で分散ストレージを組んでいる人もいるかと思います。 我が家では Synology の NAS をストレージバックエンドとして使っています。つまり、自宅に安価に箱物ストレージがある気分に浸れるのです。 (写真で青色 LED が光っているのが筐体です。オールフラッシュかつ、UPS につないで可愛がってます。)
余談ですが、Synology の公式サイトには、「個人向け」「中小企業向け」以外にも、「IT 愛好家」向けの項目があって好感が持てます。いわゆる 逸般の誤家庭 向けってやつですね。
Synology CSI Driver
昨今はコンテナオーケストレーターとストレージ機器の連携には、CSI(Container Storage Interface)を介して行われるのが一般的です。 有志によって Synology の NAS 向けの CSI Driver が公開されています。つまり、Kubernetes から Synology の NAS をバックエンドとして利用することができるようになっています。なお、iSCSI でのブロックデバイスのボリュームマウントに対応しています。ReadWriteMany で利用したい場合は、別途 NFS マウントなどを検討してください。
CSI の Document にも、Sample Drivers として取り上げられています。この Driver は Synology 社に公式サポートされているものではなく、非公式な Driver なので商用での利用などは注意したほうが良いでしょう。
Synology CSI Driver では、Synology の Volume(複数の物理 Disk を束ねた StoragePool を論理的に切り出したもの)単位で StorageClass を切って使うようになっています。そのため、Kubernetes 向けと自宅向けに分けて使うこともできます。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
# set this to false if you do not want this storage class to be default
storageclass.kubernetes.io/is-default-class: "true"
name: synology-iscsi-storage
provisioner: csi.synology.com
parameters:
location: '/volume1' # ここに Kubernetes 向けに切った Volume を指定する
type: 'BLUN'
reclaimPolicy: Retain
allowVolumeExpansion: true
CSI Driver ことはじめ
CSI Driver では Controller Plugin と Node Plugin の 2 つのコンポーネントがあります。Controller Plugin はコンテナオーケストレーターで 1 つ、Node Plugin は各ノードに 1 つ起動します。Kubernetes の場合は、Controller Plugin は StatefulSet、Node Plugin は DaemonSet で起動させることが多くなっています。Controller Plugin はどこで実行可能な処理を、Node Plugin は各ノード上で直接実行する必要があるマウントなどの処理を担当します。
CSI には仕様があり、ボリューム作成時やアタッチ時のライフサイクルや、RPCで呼ばれる関数が取り決められています。
例えば、Volume が Dynamic Provisioning でデプロイされ、Pod が起動する際の最低限の実装は下記のとおりです。リクエストが発行されると、CreateVolume() によりボリュームが作成されます。その後、ControllerPublishVolume() によりノードに対してボリュームをアタッチし、NodePublishVolume() によりノードでアタッチされたボリュームをマウントする流れになっています。削除する際には、逆の順番で行われていきます。
CreateVolume() は Controller Plugin 側で処理を行います。ControllerPublishVolume() と NodePublishVolume() はそれぞれ Controller Plugin と Node Plugin 用に用意されており、それぞれで実行します。

(なお、いくつかの CSI Driver の実装を眺めてみましたが、実際に各関数で行われている処理は Driver によってまちまちだったので注意が必要そうです。ボリュームをノードで使えるようにするまでに、Controller側での処理とNode側での処理の2つがあると考えておくと良いでしょう。)
Synology CSI Driver では、Dynamic Provisioningされた Volume は LUN として払い出されます。

VolumeExpansion の実装について
さて、本題です。
ボリューム拡張には、ControllerExpandVolume() と NodeExpandVolume() の 2つの Interface を利用します。Synology CSI Driver ではこれら2つの関数が用意されていないため、実装する必要があります。
大まかには、ControllerExpandVolume() ではストレージバックエンドにボリューム自体の拡張を行うリクエストを行い、NodeExpandVolume() ではアタッチされたボリュームのファイルシステムの拡張を行います。
Synology CSI Driver の場合、ControllerExpandVolume() では Synology の API を叩いて LUN の拡張を行います。 https://github.com/jparklab/synology-csi/pull/46/files#diff-80793083e0532aa32cf03aecc5ee3efefced14c5b0d7af3ca7cfc0b03e2b9af8R58-R124
この実装のみを入れた状態で LUN を 10GB から 15GB に拡張後にノード側でブロックデバイスの情報を見てみると、拡張された値になっていません。
root@k8s1:/# fdisk -l | grep sdb Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
ただ LUN を拡張しただけではブロックデバイスの拡張を検知できていないため、NodeExpandVolume() で rescan パスに対して書き込みを行い検知するようにします。こういった各ノード上で実行しなければならない処理のために、Controller Plugin と Node Plugin は別れています。 https://github.com/jparklab/synology-csi/pull/46/files#diff-4ff8ed7064d3ab0eae29d29d061a7a0799a0b630a9a5c76d6ab2bb333bef7124R307-R332
OpenStack Cinder CSI などでも rescan パスに対して書き込みを行い、変更を検知する実装になっています。
# 手動で実行した場合の例 root@k8s1:/# echo 1 > /sys/block/sdb/device/rescan root@k8s1:/# fdisk -l | grep sdb Disk /dev/sdb: 15 GiB, 16106127360 bytes, 31457280 sectors
ブロックデバイス拡張後には、ファイルシステムの拡張を行う必要があります。これも NodeExpandVolume() 側で行います。 ファイルシステムの拡張には、"k8s.io/kubernetes/pkg/util/resizefs" パッケージが利用できます。 https://github.com/jparklab/synology-csi/pull/46/files#diff-4ff8ed7064d3ab0eae29d29d061a7a0799a0b630a9a5c76d6ab2bb333bef7124R334-R338
このパッケージでは、内部的には resize2fs や xfs_growfs をコマンド実行で呼び出しているだけなので、Node Plugin のプログラムを実行する環境にはこれらのコマンドが必要です。 https://github.com/kubernetes/kubernetes/blob/master/pkg/util/resizefs/resizefs_linux.go#L29
なお、このパッケージを使わずに、resize2fs や xfs_growfs を直接使っている CSI 実装もありました。 思ったよりかは愚直な実装なのは少し意外でした。
今回のように Controller Plugin の処理のあとに Node Plugin 側でも Rescan や Filesystem の拡張などの処理が必要な場合、ControllerExpandVolumeResponse を返す際に NodeExpansionRequired=true で返してあげてください。 https://github.com/jparklab/synology-csi/pull/46/files#diff-80793083e0532aa32cf03aecc5ee3efefced14c5b0d7af3ca7cfc0b03e2b9af8R121-R124
これだけでは実は動きません。最後に、この CSI が VolumeExpansion に対応していることを示すように、Capabilities として登録しておく必要があります。
https://github.com/jparklab/synology-csi/pull/46/files#diff-e8a7e777d80a14b455bdbf7aae3f28ad8082ffa0a06579e11cc1af741b5f98f7R95 https://github.com/jparklab/synology-csi/pull/46/files#diff-4ff8ed7064d3ab0eae29d29d061a7a0799a0b630a9a5c76d6ab2bb333bef7124R369-R388
Synology CSI Driver の TODO
VolumeExpansion の後といえば、Snapshot の実装もしたいなと思っています。 Synology は Snapshot にも対応しているため、CSI 側に実装をいれることで使えるようになる見込みです。
また、現在は iSCSI を使った ReadWriteOnce なマウントのみサポートしていますが、共有フォルダ機能を使って ReadWriteMany な Dynamic Provisioning もサポートしたいなとも思っています。
また、今回の実装とは関係ありませんが、Synology CSI Driver を見ていていくつか修正したほうが良さそうな点がありました。 1つ目に、iSCSI Target が消えないときがあるようなのでその辺りも考慮した実装にする必要があります。 2つ目に、各 csi-provisioner や csi-resizer 単位で Pod が作られているため、sidecar をまとめた Pod にしたほうが良さそうです。
この辺りも暇を見つけて実装できたらと思います。
まとめ
今回は CSI の VolumeExpansion の実装について紹介しましたがいかがでしたか?
また、おうち Kubernetes がある方は、Synology の NAS と Synology CSI Driver を使って、更に快適な環境にしてみてはいかがでしょうか?
参考:Synology NAS について
Synology の NAS は、NFS や CIFS など様々なプロトコルをしゃべることができます。 我が家ではメディア系のファイルや PDF ファイルなどが保存されており、Mac・iPad・iPhone などからいつでもアクセスできるようにしてあります。
また、Synology の NAS には、10G NIC がついたモデルとついていないモデルの 2 つがあります。 私が購入した DS620Slim は 10G NIC がついていないモデルで、1G * 2 の NIC がついています。250 MB/s 程度までしかスループットはでませんが、DS620Slim はその名の通りかなりコンパクトな筐体に 2.5 inch disk が 6 本まで刺さるので、かなり集約率は高い筐体です。 対向の Switch 側が対応していれば Bonding にも対応しているようですが、今回はそれぞれが影響しあわないように「おうち Kubernetes が CSI 経由で使う NIC」と「NFS などで各種デバイスから接続する NIC」 で分けています。
また、Synology 独自の RAID (Synology Hybrid RAID)では 1本〜6本まで順に増やしていくことが可能なため、スモールスタートするにはうってつけです。 またディスクサイズが揃っていなくてもチャンクに分割することで最大限ディスクを使えるような仕組みになっています。
参考:Synology CSI Driver の API について
Synology API に接続するためのコードは Synology CSI Driver の pkg/synology/api/ 以下にLUN、Target、Volume を操作するための API が用意されています。ここでいう Volume は Synology の Volume(/Volume1 など)を指しています。
なお、現状の Synology CSI Driver に必要な部分しか実装されていないため、ボリューム拡張用に LUN API に Update() 関数を生やしています。
Kubernetesにおけるマルチクラスタ関連手法の分類
こんにちは。青山(amsy810)です。
Kubernetesには複数のクラスタを扱うための技術がいくつかあります。 今回は幾つかのパターンに分けて紹介していきたいと思います。 また、将来的にこうなったら面白いかもという話をするために、すぐにプロダクション利用できない話やWebサービスでは使わないような話も含まれています。
【目次】
- 複数クラスタを利用する理由
- 複数クラスタを管理するパターン
- GitOpsで複数クラスタを管理するパターン
- 複数のKubernetesクラスタをFederateするパターン
- Virtual kubeletパターン
- マルチクラスタ時のロードバランサの扱い
- LoadBalancer の機能を利用して分散する
- DNS を利用して分散する
- Multi Cluster にまたがる Service Mesh を利用して転送する
- マルチクラスタでPod Networkを繋ぐ
- ストレージの扱い
- マルチテナンシー関連の技術
- 超個体型データセンターへの応用
複数クラスタを利用する理由
複数クラスタで構成するには下記のような理由があるのではないでしょうか。 何がしたいかによっては、選択できる手法も限られてくるでしょう。
- 耐障害性、信頼性向上、ディザスタリカバリ
- マルチクラウド・ハイブリッドクラウド対応
- ジオロケーションによるパフォーマンス問題の解消
- 機密データのローカリティを確保する
- In-place クラスタアップグレードを避ける
- スケーラビリティの確保
- エッジ・フォグ環境に適用する
北山さんがマルチクラスタのメリット・デメリットでおすすめの記事をツイートしていたので、こちらもメモしておきます。
複数クラスタを管理するパターン
複数クラスタを管理する方法は主に3つあります。
1. GitOpsで複数クラスタを管理するパターン
GitOpsでは、Gitリポジトリに保存されたマニフェストファイルをKubernetesクラスタに対して同期することでKubernetesクラスタの管理を行います。 この時に、同じリポジトリを参照することで同等のクラスタを作成することができます。 また、ArgoCD では Kustomize や Helm と連携することができるため、レプリカ数や一部の設定を変更したり、一部のマイクロサービスだけデプロイするといった選択をすることも可能です。
現状プロダクションで利用するとなると、GitOpsで複数のクラスタに対してマニフェストを適用する方法を取ることが多いでしょう。

2. 複数のKubernetesクラスタをFederateするパターン
Kubernetesには、複数のクラスタを束ねて管理する Federation v2 の開発が SIG-MultiClsuter によって進められています。 Federation v2では、マネジメントクラスタが複数のターゲットクラスタを管理する形になります。 マネジメントクラスタに対して、FederatedDeploymentやFederatedServiceなどのリソースを作成すると、複数のターゲットクラスタにDeploymentやServiceが作成されるようになっています。 また、CustomResoruceなどもFederetadXXXとして扱うことができるようになっています。

Federationでも、FederatedDeploymentなどの定義時に特定のフィールドにパッチを当てることができます。 また、ClusterSelectorを使用して特定のクラスタのみにデプロイすることも可能です。
kind: FederatedDeployment
spec:
overrides:
- clusterName: cluster1
clusterOverrides:
- path: "/spec/replicas"
value: 5
- clusterName: cluster2
clusterOverrides:
- path: "/spec/template/spec/containers/0/image"
value: "nginx:1.17.0-alpine"
他にも、複数のクラスタ横断でレプリカ数を維持するようなスケジューリングを行うReplicaSchedulingPreferenceなどの機能もあります。クラスタ横断でDeploymentを柔軟に展開したい場合には利用すると良いでしょう。
apiVersion: scheduling.kubefed.io/v1alpha1
kind: ReplicaSchedulingPreference
metadata:
name: test-deployment
spec:
targetKind: FederatedDeployment
totalReplicas: 9
clusters:
A:
weight: 1
B:
weight: 2
3. Virtual kubeletパターン
Virtual kubeletはKubernetesに仮想ノードを登録し、その仮想ノード上割り当てられたPodは「クラスタ外にあるコンピューティングプール」で起動する仕組みを提供します。 コンピューティングプールは、一般的にServerlessなCaaSサービスが多いですが、他にもエッジ環境におけるノードや別のコンピューティングクラスタのケースもあります。

Virtual kubeletで扱えるコンピューティングプールには、さまざまなプロバイダーが提供されています。 大きく分けると3種類でしょうか。
Serverless CaaSバックエンド向け
- Azure Container Instances
- AWS Fargate
別コンピューティングクラスタ向け
- Admiralty Multi-Cluster Scheduler
- HashiCorp Nomad
エッジ環境・単一ノード向け
Serverless CaaS バックエンド向けのプロバイダでは、無尽蔵なコンピューティングプール上に迅速にPodをオフロードして起動するような使い方ができたり、メインで使うことでKubernetesノードを管理する必要がなくなります。 なお、AWS Fargateプロバイダーは、EKS on Fargateでは使われていません。
別コンピューティングクラスタ向けのプロバイダでは、Serverless CaaSの代わりに、HashiCorp Nomadや別のKubernetesクラスタ(Admiraltyの場合)などのコンピューティングクラスタに対してPodをオフロードすることができます。 Admiralty Multi-clsuter scheduler はその名の通り、複数のKubernetesクラスタに対してスケジューリングする用途でも使うことができます。
エッジ環境や単一ノード向けのプロバイダでは、Virtual Nodeに割り当てられたPodはエッジ環境上のクラスタで起動します。 クラウド上に起動しているKubernetes Masterから、エッジ環境のノード郡を管理できるようになります。
これらのソリューションはいくつかしか試せていませんが、全てにおいて「通常Nodeで起動したPod」と「Virtual kubeletで起動したPod」の間のPod Networkが適切に接続されたままになるのかが気になるところです。
マルチクラスタ時のロードバランサの扱い
マルチクラスタ環境では、ロードバランサなどのサービスを提供するエンドポイントを払い出す方法が大きく分けて3種類あるでしょう。
1. LoadBalancer の機能を利用して分散する
Anthos の Multi Cluster Service / Ingress では、同一IPアドレスを利用して複数リージョンにまたがる複数のクラスタに対してリクエストを転送することができます。なので、米国と日本でマルチクラスタ構成を組み、リクエスト元の地理に応じて最適なクラスタに転送することができます。マルチリージョンでマルチクラスタ構成をするにあたって、この機能は便利だなという気持ちになります。
CyberAgent の AKE でも、単一のVIPを使って複数のクラスタ上に展開されるServiceやIngressに利用できるようになっています。主にクラスタ間移行をゼロダウンタイムで行えるようにすることが目的です。

2. DNS を利用して分散する
上記のような環境が利用できない場合は、DNS Round Robin で構成するのが一般的でしょう。 Federation v2の場合は ExternalDNSと連携するようになっており、作成されたLoadBalancer Service と Ingress リソースが払い出す複数のVIPを自動的にDNSに登録する、Multi-Cluster Service DNS と Multi-Cluster Ingress DNS の機能が提供されています。

3. Multi Cluster にまたがる Service Mesh を利用して転送する
クラスタ間の距離がある程度近い場合は、特定のクラスタでリクエストを受けて隣のクラスタにリクエストを転送するようにするのも良いでしょう。 Istio ではMulti Cluster Service Meshの機能が用意されており、複数のクラスタにまたがってリクエストを分散させることができます。

マルチクラスタでPod Networkを繋ぐ
マルチクラスタでPod Networkを構成するには、Submarinerを利用することができます。 Submarinerでは、相互接続するすべてのクラスタのノード1台以上のGateway用のAgent(Submariner Gateway Engine)を展開し、このGateway Agent間でIPSecトンネルが張られるようになっています。 また、すべてのノードにはRoute Agentが展開されており、これによりクラスタを跨いだPod間通信ができるようになっています。

またSubmarinerでは、複数のクラスタで利用されるクラスタ内DNSのSuffix(cluster.local)は異なるものを指定し、ClusterIPのCIDRも別のものを指定します。 そのため、特定のクラスタから別のクラスタのServiceに対してリクエストが送れるように、双方のDNSサーバに対してクエリをかけられるようにしておく必要があります。

ストレージの扱い
マルチクラスタ・マルチテナント環境におけるストレージの扱いですが、VolumeSnapshotの機能が導入されることである程度クラスタ間移行はしやすくなるかもしれません。 一方で、CSI Driver間でのマイグレーションなどは現状はスコープ外のため、同一CSI Driver、すなわち同一のストレージバックエンドに限れば、クラスタ間でPersistentVolumeの移行もしやすくなるかもしれません。 マルチクラスタの理由にもよりますが、同一クラウドでマルチクラスタ構成であれば、シームレスな移行も夢では無いかと思います。
マルチテナンシー関連の技術
マルチクラスターと類似したものとして、マルチテナンシーの考え方もあります。 Kubernetesコミュニティにも、SIG-MultiClsuter と Multi-Tenancy WG の 2 種類があります。
下記に Virtual Cluster や Hierarchical Namespace の incubating project のDesign Docsや実装が公開されています。 GitHub - kubernetes-sigs/multi-tenancy: A working place for multi-tenancy related proposals and prototypes.
また、Hierarchical Namespace Controller については、以前検証した結果をブログにまとめてあるのでご興味があれば参考にしてみてください。
また先週末の KubeFest でぞえとろさんがちらっと話題に出してた、kioskやloft あたりも気になっています。 この辺りも時間があれば調べて、マルチクラスタ編もまとめるかもしれません。
超個体型データセンターへの応用
客員研究員として参加しているさくらインターネット研究所では、ビジョンとして「超個体型データセンター」を掲げています。 私の理解でざっくりと説明すると、「中小規模のデータセンター」や「エッジ・フォグ環境」などが相互に有機的に接続され、自律分散的に協調動作するだろうというビジョンです。
今回は備忘録的にKubernetesにおけるマルチクラスタ周りの技術の分類や手法をまとめてみました。 ベースの技術としてKubernetesを使うべきというわけではありませんが、技術検証やPoCなどではKubernetesやCRD/Controllerによる拡張性を利用できると良いかと思っています。
今回紹介したマルチクラスタ関連の技術を組み合わせることで、少しそれらしいものはできるかもしれませんが、超個体的(相互に有機的に接続され、自立分散的に協調動作)というよりかは、中央集権的な手法が多いと感じています。
そのため理想としては、各Kubernetesクラスタを作成後にAgentを各クラスタにデプロイするだけで、Agentが相互に情報を交換しあうことで最適なワークロードの配置を行ってくれるような、超個体的なクラスタを作れると面白いのかなと思っています。 Kubernetesの場合には、このAgentの実装はCustom Controllerを実装すればよいので、あとはロジックをどうするかをもう少し明確に考える必要があると思っています。 ロジックやメトリクスがPlugableにできるように設計できれば、最初は局所解に陥るような単純なものでも良いのかもしれません。

Flexispotで最大サイズの昇降机を自作した話
こんにちは。 青山(amsy810)です。
皆さん在宅勤務が長引いて大変な日々をお過ごしでしょうか。 かくいう私も仕事場所を作ってたんですが、長期かつ運動もしなくなる状況では耐えられなかったため昇降デスクを作ることにしました。 最大サイズで作った例が見当たらなかったので、まとめておきます。
最近の昇降デスクはかなり安くなってるのですね。 出来上がりはこんな感じです。
【自宅環境整備週末日記②】
— MasayaAoyama(青山 真也) (@amsy810) 2020年4月18日
はい、できました!(途中経過全然載せられなかった)
昇降すると123cmまであがるので在宅疲れの軽減に期待。
自分で作ると32インチのモニター二枚置いても広々な規格外サイズ作れて良い。
週末もいろんな意味でアーキテクト、インフラエンジニアしてました。 pic.twitter.com/Eb6s1uSdYC
どの昇降デスクを選んだのか
今回選んだのは Flexispot の E3 シリーズです。 デスクの脚だけでも売っていて、天板は自由に選択することが可能です。
天板の最大サイズは 200cm x 80cm、合計100kgまで耐えられるようです。 (ページによって80kgと書いてあるところもあるので、どちらが正しいのかは微妙) また、昇降高も60cm-123cmなのでかなり幅広く対応できます。

この脚自体が35kgくらいあるので、なかなかしっかりしています。 個人差はあるでしょうが、この高性能な脚だけで5万を切るのはなかなか安いなと思っています。 私自身中学時代からゲームばっかりしてたので、その頃から腰痛とは付き合ってますし。
木材の購入
次に木材の選定ですが、やはり目指すは最大サイズです。 でかいホームセンターなどでよく売られているお手頃な一般的な木材の多くは、大きくても 180cm x 60cm とかが多いイメージです。 豊洲のビバホームでもこのくらいのサイズが最大のようでした。
そのため、このサイズの木材に関しては無垢材(横接ぎ材)や集積材などから切り出してもらうしかありません。
今回は下記で木材を発注しました。 4/10に入金して4/17には到着したので、納期も5営業日程度とかなりスピーディーでした。
今回は木材はベイマツ集積材(米松)にしました。 一番風合いが自然だなと思ったのと直感です。
長く使うならウォルナットの無垢材に奮発しようと思っていたんですが、こちらは納期が2-3週間かかり、かつ今回はGWも跨ぐとのことだったので見送りました。 一時しのぎでベイマツ集積材にしたのですが、後述するオイルフィニッシュの出来が良かったのでこのままでも良いかなと思っています。 https://shop.woodworks-marutoku.com
強度と耐荷重について
机を作るに当たって一番気にしなければならないのは強度です。 200cm x 80cm ともなると、2cm程度の板だと流石に心許ないでしょう。 今回は 4cm の厚さで作りました。 4cmくらいあると結構しっかりしている感じですが、見た目的には3cmくらいの気分です。
200cm x 80cm x 4cm の米松の木材となると、大体45kgくらいの重さになります。 4.5cmか悩んだのですが、一人で持てる重さを考えて4cmにしたというのもあります。
ちなみにこのサイズであれば、多少力持ちであれば一人で倉庫からピックアップして車に積んで、台車を使えば家に運び込むこともできます。(個人の見解です)
現時点で床への重さは35kg(脚)+45kg(板)です。 床に対する耐荷重はここに人や椅子、モニタやモニタアームなどが加わります。 気になる方は床への耐荷重も調べておくと良いかもしれません。 調べた感じだと1m2あたり180kgまで耐えられるようなので、大丈夫かなと判断しました。
机自体の耐荷重は45kgだけなので、55kg分はモニターなどで利用することが可能です。
加工について
佐久間木材さんの場合糸面取りは無料でやってくれます。 それ以外の加工はヤスリとかを買って自分でやれば30分くらいで終わるのでおすすめです。 納品された時点で木材自体は240-400番台のヤスリでヤスリがけされていたような感じがするので、そのまま使っても大丈夫な気がします。 ただし糸面取りだけだと角が結構痛いので、多少の加工はしておいたほうが良いと思います。
NESHEXST ハンドサンダー サンドペーパー ヤスリ ホルダー 紙やすり
オイルフィニッシュについて
今回は塗装ではなく、オイルフィニッシュを行いました。 塗装ってムラができやすいのでかなり真面目にやらないとダメなんですよね… その点オイルフィニッシュであれば刷毛とキムワイプさえあればどうにかなります。
手順としても、下記のステップを踏むだけなので比較的簡単です。 塗る作業についても、サラダ油くらいのオイルを木に染み込ませて木の防御をする感じなので、ムラは出づらく楽チンでした。 私は片面塗り終わった後、もう片面は1時間位たってすぐにひっくり返して塗り始めまてしまいましたが、大丈夫そうでした。 ちなみに片面しか塗らないのは、湿気の吸い具合にむらが出て木の反りの原因になるとのことなので、両面塗りは必須です。
- 400番でヤスリがけをする
- たっぷり片面を塗る
- 30分待つ
- 二度塗りする
- 600番の耐水ペーパーで濡れたままヤスリがけ
- キムワイプで水分を完全に拭き取る(可燃性なので廃棄に注意)
- 12-24時間放置
オイルフィニッシュは着色されたやつもあります。 今回はウォルナット調のものを利用しましたが、木目がいい感じに出てくれてよかったです。
【自宅環境整備週末日記①】
— MasayaAoyama(青山 真也) (@amsy810) 2020年4月17日
さて、スタート地点となる2000mm x 800mm x 40mm の板を人気のない夜中に倉庫からピックアップしました(コロナ対策)
からのワトコオイルを塗りました。
ウォルナット無垢材は納期が長かったので、一時凌ぎで松の集積材+着色オイルにしたんですが、思ったよりいい感じ。 pic.twitter.com/md98MRxHfS
ワトコオイル ダークウォルナット W-13 1L ハンディ・クラウン 差し口ベロ 40mm
組み立てについて
脚のパーツは簡単に組み立てられます。 脚を180cmに広げた状態でも一人でも持ち上げられます。
木材と脚はネジでつなげますが、木材を付けた脚を一人でひっくり返すのは正直難しいと思います。 なので今回は木材を脚の上に載せた状態でネジ止めをしました。 今回は木材自体が重いのもあってか、この状態でもネジ止めができました。 ネジ止めするときも昇降して高い位置にしておけば、下からでも作業がしやすかったです。
感想
スタンディング、思ったより最高です。意外と疲れないんですね。 ただ思ったより足裏は痛くなるので、たしかに下に敷く厚手のマットは必要だなぁという気持ちになりました。
その他のWFH環境
| 品目 | 商品名 | オススメ理由 |
|---|---|---|
| 椅子 | アーロンチェア | 12年保証?があるので月額換算すれば安い。というか腰痛すぎて高校生のときに貯金で買いました。 |
| モニター | 328P6AUBREB/11 | 32インチ4Kくらいがちょうどいい。type-C 接続可 |
| モニターアーム | エルゴトロン | デザインよし |
| キーボード | REALFORCE | 自作したいけど、今は慣れ親しんだコレで… |
| マウス | MX Master | 言わずとしれた定番 |
| マウスパッド | steelseriaesのやつ | さらさら |
| ウェブカメラ | Logicool c922 | 画質よし |
| マイク | MPM-1000U | コスパよし |
| オットマン | Amazonで適当に | コスパ良し |
後は配線周りを工夫して、モニタの片側をiPadで利用したりなどもできるようにしています。
あと、椅子の下にはなにか敷いたほうがいいです。長い間使ってると床を結構傷つけます。ニトリのタイルマットが結構オススメで、汚れても交換簡単、安い、厚みがあるので安心です。
まとめ
備忘録+メモ書き的な感じなので乱文ですが、まとめておきました。 引き続きひきこもるぞ。
Conftest で CI 時に Rego で記述したテストを行う
Conftest で CI 時に Rego を用いたテストを行う
こんにちは。青山(@amsy810)です。 実は少しだけ PLAID さんでお手伝いをしており、CI に Conftest を組み込んで Kubernetes マニフェストのポリシーチェックを行うようにしたので、その時の備忘録を書いておきます。 PLAID さんでも GKE を基盤として選定して開発しています。
Conftest とは?
Conftest は Rego 言語で記述したポリシーを用いて、JSON や YAML などがポリシーに合致しているかをチェックする OSS です。 今回は Kubernetes のマニフェストがポリシーに合致しているかどうかを判別するために利用します。
例えば下記の例では、Deployment や StatefulSet などの Workloads リソースの Selector や起動してくる Pod のラベルに app ラベルが付与されるかをチェックしています。このように、比較的記述しやすい言語を利用してポリシーを定義していくことが可能です。
deny[msg] {
input.kind == workload_resources[_]
not (input.spec.selector.matchLabels.app == input.spec.template.metadata.labels.app)
msg = sprintf("Pod Template 及び Selector には app ラベルを付与してください(spec.template.metadata.labels.app、spec.selector.matchLabels.app): [Resource=%s, Name=%s, Selector=%v, Labels=%v]", [input.kind, input.metadata.name, input.spec.selector.matchLabels, input.spec.template.metadata.labels])
}
ポリシーチェックの実行は下記のコマンドを実行するだけなため、容易に CI に組み込むことが可能です。
# サンプルは https://github.com/MasayaAoyama/conftest-demo に配置してあります conftest test --policy ./policy --input yaml manifests/*
Rego 言語については OPA の公式サイトを見てください。
Built-in Function については下記のソースコードも参考になります。
OpenPolicyAgent / Gatekeeper との違い
類似プロダクトとして、OpenPolicyAgent / Gatekeeper もありますね。 Gatekeeper を利用したポリシーチェックでは、Kubernetes にマニフェストが登録する際に AdmissionWebhook の ValidatingWebhook が実行されるタイミングで評価されます。そのため、Mutating されたあとの状態のチェックも行うことが可能です。
GitOps の場合はマニフェストリポジトリの状態がクラスタの状態と同じ状態になるように構成します。Gatekeeper を利用していて GitOps などを行っている場合には、マニフェストのリポジトリに対してコミットした後、実際にクラスタに反映する際に失敗して初めてポリシーに違反していることが確認できます。
一方で Conftest の場合には、CI の際にチェックすることが可能です。そのため、マニフェストが適切かどうかはリポジトリにコミットする前、すなわちマニフェストファイルに対する更新時にもチェックするようにしましょう。
Gatekeeper もクラスタへの登録時に安全に防ぐようにし、GitOps などを行っている場合には Conftest で CI でも前倒しして事前にチェックするように 2 段構えにすると良いと思います。
余談ですが、GCP の Anthos Config Management で提供されている Anthos Policy Controller も Gatekeeper を利用しているようです。 https://cloud.google.com/anthos-config-management/docs/concepts/policy-controller
設定しているポリシーについて
下記のようなポリシーを設定しています。一部は PodSecurityPolicy でも設定可能ですが、PSP も Gatekeeper 同様 Kubernetes API 登録時にチェックが行われるため、Conftest でもチェックすることに意味はあるでしょう。
- 単一リソース内でのチェック
- 特権コンテナの利用制限
- 各種リソースや Selector に特定のラベルが付与されているかのチェック
- コンテナのイメージタグの制限
- TerminationGracePeriodSeconds の設定時間が既定値以下かのチェック
- Resource Requests が設定されているかのチェック
- Limits/Requests の差のチェック
- Probe の failureThreshold などの設定値が既定値の範囲内かのチェック
- Inter-pod anti-affinity が設定されているかのチェック
- hostPath 利用時に Readonly になっているかのチェック
- Service の ClusterIP が静的に設定されていないかのチェック
- Ephemeral Storage の利用上限設定がされているかのチェック
- etc
- クラスタ全体での横断チェック
- ラベルがバッティングしていないか
- etc
Gatekeeper とのポリシーファイルの違い
Gatekeeper の場合には、現在既に Kubernetes に登録されているデータを data.inventory から参照することが可能です。
クラスタオブジェクトの場合: data.inventory.cluster[<groupVersion>][<kind>][<name>] (例: data.inventory.cluster["v1"].Namespace["gatekeeper"]) Namespace オブジェクトの場合: data.inventory.namespace[<namespace>][groupVersion][<kind>][<name>] (例:data.inventory.namespace["gatekeeper"]["v1"]["Pod"]["gatekeeper-controller-manager-d4c98b788-j7d92"])
これを利用すると、下記のように既に登録されている Ingress リソースの host 名と衝突していないかといったチェックも行うことができます。
# https://github.com/open-policy-agent/gatekeeper/blob/master/library/general/uniqueingresshost/src.rego
package k8suniqueingresshost
identical(obj, review) {
obj.metadata.namespace == review.object.metadata.namespace
obj.metadata.name == review.object.metadata.name
}
violation[{"msg": msg}] {
input.review.kind.kind == "Ingress"
re_match("^(extensions|networking.k8s.io)$", input.review.kind.group)
host := input.review.object.spec.rules[_].host
# 既にクラスタに登録されているデータを参照
other := data.inventory.namespace[ns][otherapiversion]["Ingress"][name]
re_match("^(extensions|networking.k8s.io)/.+$", otherapiversion)
other.spec.rules[_].host == host
not identical(other, input.review)
msg := sprintf("ingress host conflicts with an existing ingress <%v>", [host])
}
Conftest による横断のチェック
さて、本ブログ記事で一番お伝えしておきたい内容です。 実際マイクロサービスが複雑化してくると、Conftest の段階で「Deployment に対して PodDisruptionBudget が設定されているか」「Service の Selector にマッチする Deployment 等が存在するか」「横断でラベルがバッティングしていないかのチェック」といった横断的なチェックを機械的に行わなければ予期せぬ障害が発生するかもしれません。
Conftest でも --combine オプションをつけることで複数のファイルをロードして横断でチェックすることが可能です。
conftest test --policy ./policy --input yaml ./manifests/* --combine
このとき、conftest にはリソース自体が入ってくるのではなく、「ファイル」「リソース」の配列で入ってくるため注意してください。なお、ひとつのファイルに単一リソースしか書かれていない場合は、「ファイル」の配列の後にそのままリソースが入ってきてしまい、ファイルによって構造が変わってきてしまいます。そのため、一つのファイルに単一のリソースしかない場合でも --- を 1 つ目のリソースの後に明示的に記載するようにしましょう。
deny[msg] {
files := input[_]
resources := files[_]
other_files := input[_]
other_resources := other_files[_]
resources.kind == workload_resources[_]
other_resources.kind == workload_resources[_]
resources.spec.template.metadata.labels == other_resources.spec.template.metadata.labels
resources.metadata.name != other_resources.metadata.name
msg = sprintf("リソースのラベルが衝突しています: [%s/%s <=> %s/%s]", [resources.kind, resources.metadata.name, other_resources.kind, other_resources.metadata.name])
}
まとめ
Conftest は非常に手軽に CI にマニフェストのチェックを導入できるためおすすめです。また、OPA のポリシーファイルを使い回しやすいため、OPA と合わせて利用する際もそこまでコストを掛けずに利用することが可能です。ぜひセキュリティや組織ポリシーの徹底のためにも、OPA / Gatekeeper と合わせて Conftest の利用を検討してみてください。
今回利用したサンプルファイル類は下記に上げています。
EKS on Fargate:virtual-kubelet の違い + Network/LB 周りの調査
EKS on Fargate
こんにちは。 サイバーエージェントの青山(@amsy810)です。
この記事は Kubernetes3 Advent Calendar の 4日目の記事です(EKS #2 にもクロスポストしています)。 re:Invent で EKS 関連の何かしらの発表がされることを見越して Advent Calendar を埋めたので、書くネタが見つかってホッとしています。
KubeCon 会期中に 「Managed Worker Node for EKS」 がリリースされ歓喜の声が上がりましたが、今回は re:Invent で 「EKS on Fargate」 がリリースされ歓喜の声が上がっているようです。 今回は EKS on Fargate のアーキテクチャを見ていきたいと思います。virtual-kubelet と近いと思ってますが果たして。 (EKS on Fargate の詳細な記事はプロの誰かが書くと思うので、私は主に virtual-kubelet との対比と、大好きなネットワーク周りの軸でかければと思います。)
EKS on Fargate とは?

EKS on Fargate は 12/3 PST にリリースされた、AWS Fargate をバックエンドとして、Kubernetes Pod を起動することができる機能です。Fargate がいることにより、EC2インスタンスを管理する必要がなくなります。よしなにやっておいてほしい人からすると嬉しいのではないでしょうか。 https://aws.amazon.com/jp/blogs/aws/amazon-eks-on-aws-fargate-now-generally-available/
ご存知の方もいるかと思いますが、ここまで聞くと類似プロダクトとして、OSS で開発が進められている virtual-kubelet(https://github.com/virtual-kubelet/virtual-kubelet) のようにも聞こえますね。virtual-kubelet は、Kubernetes の Node として1台の仮想的なノードを追加しておきます。その仮想ノードの後ろには、膨大なコンピューティングリソースを持ったコンテナ実行基盤(プール)のようなものが待ち構えており、その仮想ノードにスケジューリングされた Pod はそのリモートノード上で Pod が実行されるようになります。代表的な実装例としては、Microsoft Azure の ACI などでしょうか。

{kind=link}
virtual-kubelet のプロバイダーの中に AWS Fargate Provider もあるのを把握していたため、これが EKS on Fargate だと思っていましたが、どうやら違うようです。 リポジトリ(https://github.com/virtual-kubelet/aws-fargate)をみても、半年〜1年程度更新がないため、virtual-kubelet 経由のものよりかは、EKS on Fargate を使っていくべきでしょう。
EKS on Fargate の検証
検証環境は下記のとおりです。
- eksctl: 0.11.0-rc.0
- Kubernetes: v1.14.8-eks
クラスタの構築時に --fargate オプションを利用することで構築可能です。リリース時点から ap-northeast-1 でもデプロイ可能でした。
$ eksctl create cluster --name amsy810-cluster --region ap-northeast-1 --fargate
しばらくすると、EKS クラスタの構築が完了します。初期段階では coredns だけ起動している状態なため、2 Pod だけが立ち上がっている状態です。
# (一部アウトプットを省略) $ kubectl get pods -A -o wide NAME READY STATUS IP NODE coredns-6d75bbbf58-5jn27 1/1 Running 192.168.129.12 fargate-ip-192-168-129-12.ap-northeast-1.compute.internal coredns-6d75bbbf58-96nbt 1/1 Running 192.168.166.59 fargate-ip-192-168-166-59.ap-northeast-1.compute.internal
ノードの状態を見てみると 下記の通り 2 台だけ起動している状態です。
# (一部アウトプットを省略) $ kubectl get node -o wide NAME STATUS ROLES VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME fargate-ip-192-168-129-12.ap-northeast-1.compute.internal Ready <none> v1.14.8-eks 192-168-129-12 <none> Amazon Linux 2 4.14.152-127.182.amzn2.x86_64 containerd://1.3.0 fargate-ip-192-168-166-59.ap-northeast-1.compute.internal Ready <none> v1.14.8-eks 192-168-166-59 <none> Amazon Linux 2 4.14.152-127.182.amzn2.x86_64 containerd://1.3.0
EKS on Fargate では、virtual-kubelet とは異なり Pod 1つにつき 1 Node が展開される ような形になっています。virtual-kubelet の場合には、「kubectl get node」した際に、1 つの大きな 仮想 Node だけが存在しており、その仮想 Node 上で複数の Pod が起動するような形になるため、異なるポイントです。また、Fargate Node の IP と Pod の IP は同じになっています。他にも、各 Node の Pod Capacity が 1 になっていたり、「eks.amazonaws.com/compute-type=fargate:NoSchedule」 taints も付与されていました。
なお、当然ですが下記のような 2 Container in 1 Pod な Pod も、1 つの Fargate Node にデプロイされます。
cat << _EOF_ | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: sample-2pod
spec:
containers:
- name: nginx-container
image: nginx:1.12
- name: redis-container
image: redis:3.2
_EOF_
# (一部アウトプットを省略) $ kubectl get pods sample-2pod -o wide NAME READY STATUS IP NODE sample-2pod 2/2 Running 192.168.151.223 fargate-ip-192-168-151-223.ap-northeast-1.compute.internal
Fargate で起動する Pod の選択
EKS on Fargate では、通常ノードではなく Fargate で起動する Pod を設定しておきます。例えば、eksctl で作られるクラスタのデフォルト では default namespace と kube-system namespace にスケジューリングされる Pod は Fargate 側で実行されるようになっています。そのため、事前に条件を設定していない Namespace や Pod Selector にマッチしていない Pod の場合には、Fargate 側で実行されない点だけ注意が必要です。現状だとすべての Namespace という設定はできなさそうですが、いずれ対応されるんじゃないかなと思います(12/4 18:00 追記:既に Tori さんから Issue 化されていると教えていただきました!流石!)。設定は EKS の管理画面または「aws eks create-fargate-profile」コマンドから設定可能です。

ちなみに少し細かい話です。最初は MutatingWebhook 等で scheduling Policy(nodeAffinity、taints 等)を書き換えてるのかと思っていましたが、そもそも default scheduler を利用していないようです。Pod 登録時に該当するものは spec.schedulerName だけ Mutating して後は独自スケジューラにまかせているんだと思います。
$ kubectl get pods sample-2pod -o jsonpath="{.spec.schedulerName}"
fargate-scheduler
EKS on Fargate の起動時間
EKS on Fargate での Pod の起動時間は大体 45-50 sec 程度でした(数回のみの施行)。ノードを増やしていくことと比較すると、かなり早くコンテナを起動できるといえます。この点は virtual-kubelet の利点の一つである、クラスタ外の warmpool で起動させる部分と同じような形です。
initContainer と emptyDir の使用
ちょっと発展的に initContainer や emptyDir を使用してみましたが、こちらも問題なく動作するようです。基本的に後述する注意点以外は普通の Kubernetes だなぁという使用感なのかと思います。
cat << _EOF_ | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: sample-initcontainer
spec:
initContainers:
- name: output-1
image: centos:6
command: ['sh', '-c', 'sleep 20; echo 1st > /usr/share/nginx/html/index.html']
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html/
- name: output-2
image: centos:6
command: ['sh', '-c', 'sleep 10; echo 2nd >> /usr/share/nginx/html/index.html']
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html/
containers:
- name: nginx-container
image: nginx:1.12
volumeMounts:
- name: html-volume
mountPath: /usr/share/nginx/html/
volumes:
- name: html-volume
emptyDir: {}
_EOF_
kubectl exec による任意のコマンド実行と kubectl port-forward
Fargate ではコンテナ内のデバッグがしづらいみたいな話をよく耳にします。kubectl exec も出来ないのだろうかと不安になりましたが、kubectl exec は通常通りできるようです。これはもはやほぼ Kubernetes ですね。
$ kubectl exec -it sample-initcontainer -- cat /usr/share/nginx/html/index.html 1st 2nd
同様に kubectl port-forward や logs なんかも動きます。kubelet が Fargate 側にいそうな霊圧を感じますね。
$ kubectl port-forward sample-2pod 30080:80 $ kubectl logs sample-2pod -c nginx-container
現状の注意点
現状では、ここ にかかれている通り、下記の制約があるようです。まだファーストリリースなので、下記の要件で合わない方は AWS の早い機能追加に期待というところですね。
- ポッドごとに最大 4 vCPU 30 Gb Memory の制約
- 永続ボリュームまたはファイルシステムを必要とするステートフルワークロードは非サポート
- DaemonSet、Privileged Pod、HostNetwork、HostPort などは利用不可
- 使用可能なロードバランサーは、Application Load Balancer のみ
ALB Ingress
EKS on Fargate で払い出される Pod の IP Address 帯は Subnet のものになっているため、従来どおり ALB から疎通可能なのでしょう(Container-native Load Balancing となる type: ip 前提)。一方で "type: LoadBalancer" Service も仕組み的には kube-proxy(の iptables 等) で DNAT されているだけなので、遠くない将来にいずれ実現されるんじゃないかなと思います。
または、通常 Node が一台以上あれば、 LB からそのノードに転送された後、kube-proxy が Pod 宛に DNAT して Fargate 側に転送されて上手くいくのでは…?という気もしているので、実験してみましょう(偏るという話は置いておいて)。
更に NodeGroup を追加してハイブリット構成にしてみる(type: LB も試してみる)
というわけで、まず NodeGroup を追加します。
$ eksctl create nodegroup --cluster amsy810-cluster
するとノードの一覧はこんな感じになります。
$ kubectl delete pod --all $ kubectl get node NAME STATUS ROLES AGE VERSION fargate-ip-192-168-129-12.ap-northeast-1.compute.internal Ready <none> 3h35m v1.14.8-eks fargate-ip-192-168-166-59.ap-northeast-1.compute.internal Ready <none> 3h33m v1.14.8-eks ip-192-168-6-3.ap-northeast-1.compute.internal Ready <none> 5m29s v1.14.7-eks-1861c5 ip-192-168-72-240.ap-northeast-1.compute.internal Ready <none> 5m29s v1.14.7-eks-1861c5
試しに "type: LoadBalancer" Service と Deployment をデプロイしてみましょう。
$ kubectl apply -f https://raw.githubusercontent.com/MasayaAoyama/kubernetes-perfect-guide/master/samples/chapter06/sample-deployment.yaml $ kubectl apply -f https://raw.githubusercontent.com/MasayaAoyama/kubernetes-perfect-guide/master/samples/chapter06/sample-lb.yaml $ kubectl get pods -o wide NAME READY STATUS IP NODE sample-deployment-6cd85bd5f-4hwtt 1/1 Running 192.168.100.80 fargate-ip-192-168-100-80.ap sample-deployment-6cd85bd5f-pkn6b 1/1 Running 192.168.153.79 fargate-ip-192-168-153-79.ap sample-deployment-6cd85bd5f-xktr6 1/1 Running 192.168.130.33 fargate-ip-192-168-130-33.ap $ kubectl describe svc sample-lb | grep Endpoints Endpoints: 192.168.100.80:80,192.168.130.33:80,192.168.153.79:80
結論として、やはり読みどおり "type: LoadBalancer" も Worker Node があれば動くには動くようです。内部の実装上は、LB から Worker Node に転送された後、kube-proxy が DNAT で 各 Pod 宛に通信を転送するだけなので、Fargate Node まで VPC 経由で疎通する仕組み上、疎通しているのだと思います。Fargate がどこにあるか次第ですが、Hop数自体は Kubernetes の Node またぎと同等なので、そこまでレイテンシは乗らないんじゃないかなと思っています。この仕組だと、Fargate + 通常 WorkerNode 両方に振り分けることもできそうですね。この方法がサポート対象な方法なのかは分かりません。
$ kubectl get svc sample-lb NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE sample-lb LoadBalancer 10.100.69.184 xxx-yyy.ap-northeast-1.elb.amazonaws.com 8080:30082/TCP 5m15s $ curl -I http://xxx-yyy.ap-northeast-1.elb.amazonaws.com:8080 HTTP/1.1 200 OK Server: nginx/1.12.2
なお、同様に ClusterIP も Pod 宛に転送されるだけなので、通常通り動きます。上手く出来ていますね。
まとめ
EKS on Fargate では、virtual-kubelet とは異なる形で実装されました。virtual-kubelet を実装しようとするとベンダー毎の違いがかなり大きいはずなので、なかなか皆で足並みを揃えて進めるのは難しかったのではないかなと思います。また、virtual-kubelet の kubelet バージョン(Kubernetes API バージョン)の追従という心配もなくなり、AWS におまかせできるという大きなメリットもあります。
EKS on Fargate を少し触った所感では、Warmpool された Kubernetes Node が後ろに待機していてくれるイメージに近いので、より PaaS っぽく Kubernetes を使いやすくなるんじゃないかと思います(周辺エコシステムや CI/CD 等の整備は必要ですが)。
また、EKS は拡張性が高い反面、手放しで利用するには少しハードルがありましたが、最近は様々な機能開発で簡単に使う手段も増えてきて導入ハードルが下がってきたなと印象です。AWS Container Roadmap(https://github.com/aws/containers-roadmap)にも Managed 系の Issue がたくさん上がっているので、拡張性を重視した使い方はもちろんですが、利便性の高い使い方も今後も増えていくのではないでしょうか。
(いろんな Kubernetes のアーキテクチャが出てきて楽しいぞ)
Fargate profile なくても動くのでは…?と言われたので試しました(12/4 16:50 追記)
ということは、Fargate Profile 作らなくても直接 schedulerName: fargate-scheduler を指定すれば Pod が立ち上がるのでは…?
— チェシャ猫 (@y_taka_23) 2019年12月4日
ちゃんと Scheduler の方で Profile も見ているようですね。なんか悪いこと(抜け道探し)してる気分になってきました。
$ kubectl create ns newone
$ cat << _EOF_ | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: sample-pod-manual-fargate
namespace: newone
spec:
schedulerName: fargate-scheduler
containers:
- name: nginx-container
image: nginx:1.12
_EOF_
$ kubectl describe pods sample-pod-manual-fargate -n newone
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> fargate-scheduler Misconfigured Fargate Profile: pod does not have profile label eks.amazonaws.com/fargate-profile
$ cat << _EOF_ | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: sample-pod-manual-fargate
namespace: newone
labels:
eks.amazonaws.com/fargate-profile: fp-default
spec:
schedulerName: fargate-scheduler
containers:
- name: nginx-container
image: nginx:1.12
_EOF_
$ kubectl describe pods sample-pod-manual-fargate -n newone
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> fargate-scheduler Misconfigured Fargate Profile: pod's namespace does not match the ones listed in fargate profile fp-default
何が嬉しいのか考えてみた(追記:随時更新します)
- ノードの種別管理とかは不要になり、ピッタリなサイズでサービスを提供できる(4core? 8core? とか)
- ノイジーネイバーの影響も受けにくい(Fargate 側では集約しているので、そこの影響はあるかも)
- Pod単位でノードがいるので、通常のノードでぴったりにしようとした際に発生するオートスケーラのスケールインの影響みたいなものを受けない
Hierarchical Namespace で Namespace を階層構造に管理してオブジェクトを伝搬させる
(12/4 11:00 requiredChild について追記)
こんにちは。CyberAgent の青山(@amsy810)です。
この記事は Advent Calendar 1日目の記事です。 毎回なぜ一日目にしてしまったんだろうかと後悔します。
今回は、KubeCon + CloudNativeCon NA 2019 で併設実施された Kubernetes Contributors Summit で聞いて気になっていた、Kubernetes Multi-tenancy WG で開発が進められている、Hierarchical Namespace のお話をします。
一言で言うならば、これは 「Namespace に階層構造の概念を取り入れて、ポリシーやSecretなどのリソースを伝搬させる仕組み」 です。 マイクロサービスチームや組織構造の都合上、同じオブジェクト(ConfigMap, Namespace, ResourceQuota, LimitRange, NetworkPolicy)を登録しておきたいケースは多々あると思います。 また、RBAC の設定を伝搬させることで、下位のチームに権限移譲の設定を上手く扱うことも可能です。
事前準備
事前準備として kubectl と kustomize をインストールしておいてください。 また、今回は下記のバージョンで実施しました。
- Kubernetes: v1.16.0
- Kustomize: v3.4.0
- Hierarchical Namespace Controller: 7db19627f5d21a7a368beaa9d7b9be177d5bb26a (Git commit hash)
Hierarchical Namespace Controller (HNC)のインストール
Hierarchical Namespace Controller は Multi-tenancy WG のリポジトリの中にディレクトリが切られ、開発が進められています。 なお、Hierarchical Namespace Controller は現状まだ "very early software" と言われている通り、PoC 相当の Controller です。
https://twitter.com/aludwin/status/1196520861554991104?s=20
ソースコードを落としてきて、make deploy することでクラスタにインストールする事が可能です。今回は、 masayaaoyama/hnc-controller:7db1962 にビルドしたイメージを公開してあります。
cd git clone https://github.com/kubernetes-sigs/multi-tenancy.git # curl -o https://raw.githubusercontent.com/kubernetes-sigs/multi-tenancy/master/incubator/hnc/hack/hnc.yaml cd multi-tenancy/incubator/hnc IMG=masayaaoyama/hnc-controller:$(git rev-parse --short HEAD) GOPATH=~/go make deploy
階層化された Namespace の作成
Namespace を作成します。今回は特定のプロジェクトの Namespace (sample-project)を起点として、3階層で構成されている構造を作り出します。
root の Namespace を作成したら、それぞれに親子関係を作るため、 kubectl hnc コマンドを実行します。なお、このコマンドは kubectl plugins が make deploy した際にインストールされています。 実質的には後で説明する HierarchyConfiguration リソースの操作をしているだけです。
kubectl hnc set sample-project --requiredChild team-a kubectl hnc set sample-project --requiredChild team-b kubectl hnc set team-a --requiredChild team-a-service1 kubectl hnc set team-a --requiredChild team-a-service2 kubectl hnc set team-b --requiredChild team-b-service1 kubectl hnc set team-b --requiredChild team-b-service2 kubectl hnc set team-b --requiredChild team-b-service3
作成したあとに、Namespace の階層構造を確認してみると、下記のとおりです。 正しく3層の構造が出来ていることが確認できます。
$ kubectl hnc tree --all-namespaces
cert-manager
default
docker
hnc-system
kube-node-lease
kube-public
kube-system
sample-project
├── team-a
│ ├── team-a-service1
│ └── team-a-service2
└── team-b
├── team-b-service1
├── team-b-service2
└── team-b-service3
--requiredChild を指定して作成した Namespace が消された場合、reconcile されて再度 Namespace が作成されます。また、「kubectl hnc set team-a --parent sample-project」というコマンドで、この Namespace 作成の reconcile を無効化した状態で階層構造を作ることも可能です。
$ kubectl delete ns team-a
namespace "team-a" deleted
$ kubectl hnc tree sample-project
sample-project
├── team-a
│ ├── team-a-service1
│ └── team-a-service2
└── team-b
├── team-b-service1
├── team-b-service2
└── team-b-service3
ポリシーの伝搬の確認
今回は、ConfigMap リソースを作成し、正しくオブジェクトが伝搬していることを確認します。 sample-project 直下に作成した web-config オブジェクトは 8 つの Namespace(伝搬したのは 7 つ)に作られているのに対し、team-a 直下に作成した web-config2 オブジェクトは 3 つの Namespace(伝搬したのは 2 つ)に作られています。
$ kubectl -n sample-project create configmap web-config --from-literal=connection.max=100 $ kubectl -n team-a create configmap web-config2 --from-literal=connection.max=200 # 並び順は見やすいように変えています $ kubectl get configmap -A | grep "web-config " sample-project web-config 1 57s team-a web-config 1 57s team-a-service1 web-config 1 57s team-a-service2 web-config 1 57s team-b web-config 1 57s team-b-service1 web-config 1 57s team-b-service2 web-config 1 57s team-b-service3 web-config 1 56s team-a web-config2 1 42s team-a-service1 web-config2 1 42s team-a-service2 web-config2 1 42s
ポリシー系のオブジェクトのみ親から子へ Sync される様になっています。
伝搬対象のオブジェクトは、下記の 7 種類です。 https://github.com/kubernetes-sigs/multi-tenancy/blob/master/incubator/hnc/pkg/config/gvk.go#L14
var GVKs = []schema.GroupVersionKind{
{Group: "", Version: "v1", Kind: "Secret"},
{Group: "rbac.authorization.k8s.io", Version: "v1", Kind: "Role"},
{Group: "rbac.authorization.k8s.io", Version: "v1", Kind: "RoleBinding"},
{Group: "networking.k8s.io", Version: "v1", Kind: "NetworkPolicy"},
{Group: "", Version: "v1", Kind: "ResourceQuota"},
{Group: "", Version: "v1", Kind: "LimitRange"},
{Group: "", Version: "v1", Kind: "ConfigMap"},
}
なお、"type: kubernetes.io/service-account-token" の Secret は除外されています。 https://github.com/kubernetes-sigs/multi-tenancy/blob/7db19627f5d21a7a368beaa9d7b9be177d5bb26a/incubator/hnc/pkg/controllers/object_controller.go#L303-L326
個人的には ServiceAccount も sync してほしい気がしますが、何かしらの理由があるのでしょう。
階層構造の仕組み
階層構造は HierarchyConfiguration リソースを利用して実現しています。 このリソースには、 spec.parent と spec.requiredChildren のフィールドが用意されており、kubectl hnc set team-a --requiredChild team-a-service1 および kubectl hnc set team-a --requiredChild team-a-service2 コマンドを実行すると、 team-a Namespace に hierarchy という名前の HierarchyConfiguration リソースが作成されます。 また、status にはその Namespace の子 Namespace が追加されるようになっています。
$ kubectl get hierarchyconfigurations -n team-a hierarchy -o yaml apiVersion: hnc.x-k8s.io/v1alpha1 kind: HierarchyConfiguration metadata: creationTimestamp: "2019-11-30T16:27:49Z" generation: 5 name: hierarchy namespace: team-a resourceVersion: "20753" selfLink: /apis/hnc.x-k8s.io/v1alpha1/namespaces/team-a/hierarchyconfigurations/hierarchy uid: 29a4e049-85fa-4e95-adb3-3826a6fe1255 spec: parent: sample-project requiredChildren: - team-a-service1 - team-a-service2 status: children: - team-a-service1 - team-a-service2
なお、子 Namespace にコピーされたオブジェクトには、コピー元の親 Namespace 名がラベルとして付与されています( hnc.x-k8s.io/inheritedFrom )。
$ kubectl -n team-a-service1 get configmap web-config2 -o yaml
apiVersion: v1
kind: ConfigMap
metadata:
annotations:
labels:
hnc.x-k8s.io/inheritedFrom: team-a
data:
connection.max: "100"
なお、sample-project から伝搬されている web-config team-a のデータを消した場合は、team-a 配下の Namespace の web-config オブジェクトがすべて削除されます。
$ kubectl delete configmap web-config -n team-a configmap "web-config" deleted $ kubectl get configmap -A | grep "web-config " sample-project web-config 1 48m team-b-service1 web-config 1 48m team-b-service2 web-config 1 48m team-b-service3 web-config 1 48m team-b web-config 1 48m
プロポーザルには「HNCによって伝播されるオブジェクトは、変更または削除できない」と書いてありましたが、現状は削除可能になっています。 現状では、子の Namespace に登録されているリソースを削除できてしまうので削除すると、復元されないので注意してください。将来的には ValidationWebhook などが入るのだと思います。
なお、親 Namespace のオブジェクトを削除した場合は、子 Namespace のオブジェクトも再帰的に削除していきます。
もう少し DeepDive
Hierarchical Namespace Controller (HNC)は大きく分けて下記の 2 つの Controller( Hierarchy Controller , Object Controller )から構成されています。 kube-controller-manager と同じような構成ですね。
- Hierarchy Controller
- HierarchyConfiguration から Namespace の階層構造を status に書き込む
- 同様に Labels の付与なども行っている
- Object Controller
- 親 Namespace のオブジェクトを子 Namespace にコピーするコントローラ
Hierarchy Controller
reconcile 関数はこの辺りから。 https://github.com/kubernetes-sigs/multi-tenancy/blob/master/incubator/hnc/pkg/controllers/hierarchy_controller.go#L104
実際に Label を付与したり、status を更新する処理は下記のあたりから呼び出されています。(書き込みは別途) https://github.com/kubernetes-sigs/multi-tenancy/blob/master/incubator/hnc/pkg/controllers/hierarchy_controller.go#L149
Object Controller
Recncile 関数はこの辺りから。 https://github.com/kubernetes-sigs/multi-tenancy/blob/7db19627f5d21a7a368beaa9d7b9be177d5bb26a/incubator/hnc/pkg/controllers/object_controller.go#L51
オブジェクトをコピーしてるのはこの辺り。(inst オブジェクトを dests[] namespaces にコピー) https://github.com/kubernetes-sigs/multi-tenancy/blob/7db19627f5d21a7a368beaa9d7b9be177d5bb26a/incubator/hnc/pkg/controllers/object_controller.go#L217-L252
GCP の Anthos でも階層構造の伝搬の仕組みがあるらしい?
また、Anthos Config Management にも同様に階層構造に伝搬するように、Gitリポジトリ内で階層構造を作って同様のことをしているようです。(Anthos 触ってみたい)
Google’s Anthos Config Management (ACM) supports a similar model to this proposal by modelling a namespace hierarchy in the filesystem of a monolithic Git repo, and copies objects from parent namespaces to child namespaces in a K8s apiserver. By contrast, the Hierarchical Namespace Controller (HNC) operates entirely within a K8s apiserver and makes use of CRDs in the namespaces to express hierarchy.ACM may allow the use of HNC in the future if it becomes sufficiently mature.
より詳しく知りたい方は
これ以上の詳細は下記の Design Docs に載っています。興味のある方はぜひ見てみてください。 (12/1 が過ぎてしまうので、この辺りで…) https://docs.google.com/document/d/10MZfFfbQMm33CBboMq2bfrEtXkJQQT4-UH4DDXZRrKY/edit#
Kubernetes は辛いのか?
こんにちは。 @amsy810 です。
下記のブログが出てから『Kubernetes は運用しきれない』と耳にすることが多くなってきたので、雰囲気で曲解されて Kubernetes is difficult とならないよう、マネージドでシンプルに使うだけなら難しくないよと伝えるために書きました。
Kubernetes がいいよと伝えるためではありません。
TL;DR
上記のブログについては概ね同意見です。
辛いのは自前で Kubernetes クラスタの管理自体を行う場合です。
GKE などのマネージド Kubernetes サービスを利用するケースでは、Kubernetes の管理は殆ど必要がなくなります。
例えば GKE の場合には、自動クラスタアップグレード・自動クラスタスケーリングなどが用意されています。他にも自動ノードプロビジョニング機能(CPU・メモリ・GPU の割り当て要求に従って、良い感じのノードを自動でクラスタに追加・削除する)を利用すると ノードの管理ですら必要なくなり 、抽象度の高い(利便性の高い)基盤として利用することが可能です。
また、アプリケーション開発者として Kubernetes を利用するだけなら実際は非常にシンプルに利用することが可能です。
マネージド Kubernetes を使えるなら、開発者として利用するだけなのでそこまで難しくありません。
前提条件
コンテナを利用するべきかや、Nomad・ECS・Kubernetes といったオーケストレータ(あるいは Fargate など)を利用するべきか否かというところについては述べません。この辺りが必要な方向けに書いています。なんだかんだ VM のワークロードが必要というケースも多々あるでしょう。また、PaaS も良いと思います。あくまでコンテナオーケストレータだけの話をしています。
この前提は、再現性・管理性・復元力・可観測性・自動化・疎結合性といった特性を組織が享受できる状態か(享受したい状態か)どうかによって異なります。
なお、すでにクラウドを利用している組織で新規プロジェクトの技術選定なのだとしたら、ステートフルなものはマネージドサービスを利用しつつステートレスなアプリケーションに利用していくことは障壁も少なくおすすめです。
どのオーケストレータを選択すべきか
国内では選択したオーケストレーターを今後も長く使っていくケースが非常に多くなるかと思います。
海外では大規模なクラウド間の移行やプラットフォームの移行をやってのけるケースも多々あるため、その気概があるなら正直何から始めてもいいと思います。
日本にはなかなか真似できない部分ですね。
なるべく塩漬けにしたい場合には、「拡張性がある」「コミュニティが活発」「エコシステムが豊富」といったあたりの長く利用できるかどうか、やりたいことが増えた際に魔改造しないで済むかどうかという点を考慮すべきだと思います。
OSS だと下火になった際の影響が大きいため、選択肢がいくつかある際は個人的にはこういったところを重視しています。
ECS などのマネージドサービスに関しては、今後もあまり心配はないと思います。
ただ忘れないで欲しいのが、Kubernetes であっても アプリケーション開発者から見ると「シンプルにも利用可能」 であるという点です(あとで紹介します)。
でも流石に PaaS の利便性には勝てないとは思います。あくまでオーケストレータを純粋に比較した場合です。
オンプレで Kubernetes を選択するべきか?
オンプレ上で Kubernetes をやろうとするのであれば、少なくとも少人数で選択することはオススメしません。
やるとしてもサポート付きの商用 Kubernetes ディストリビューションを利用するか、Kubernetes を専門に面倒をみるチームが必要でしょう。
trivago さんのケースでも 4 人チームでオンプレ上に構築して利用するというものだったので、Kubernetes はかなりオーバーだと思います。
利用者としての Kubernetes
Kubernetes を利用するということは、 GCP・AWS・Azure といったパブリッククラウドを利用するのと近しいもの だと考えています。
そのため、当然パブリッククラウド自体を自前で構築して運用することを少人数で成し遂げることは困難です(例:OpenStack)。
一方で利用者から見るとパブリッククラウドは非常に便利かつ高機能ですね。
そのためアプリケーション開発者がどの環境でやるのが一番楽かという面では、マネージド Kubernetes サービスを利用するのが一番だと思います。
管理された Kubernetes 上でコンテナを起動させる場合、コンテナを起動させてくれる抽象度の高いマネージドサービスと余り差はない と思います。
例えば、シンプルに利用するだけであれば Kubernetes でも 下記のように Deployment リソース(コンテナを起動する)と Service リソース(ロードバランサ)の2つだけを使っても達成できます。
パブリッククラウドでも全ての機能を把握して選択することはないのと同様に、そのほかのリソース(機能)に関してはやりたいことが出来た際にやり方を調べれば良いと思います。その時にできることがたくさんあった方が良いとは思います。
--- apiVersion: apps/v1 kind: Deployment metadata: name: sample-deployment spec: replicas: 3 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:1.13 ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: sample-lb spec: type: LoadBalancer ports: - name: "http-port" protocol: "TCP" port: 80 selector: app: sample-app
なおCI/CD では、上記の様なマニフェストのボイラープレートを作って使い回すことが可能です。
Kubernetes を採択する規模は?
規模が大きい方が得られる恩恵は大きくなりますが、小さい規模でも恩恵は大きいと思います。
ただし、小さい規模の場合は人員も少ないため、そこを担当できる(したい)エンジニアがいるかという点につきますね。
Kubernetes は抽象度の高い環境を提供できるか?
Kubernetes も HorizontalPodAutoscaler・ClusterAutoscaler や Knative などを利用することにより、PaaS のような抽象度の高い(利便性の高い)環境を提供することは可能です。
いわゆる Fargate に近しい何かも設定次第では実現できます。
Kubernetes へ移行するべきか?
Nomad・ECS・Kubernetes など様々なコンテナオーケストレータが存在します。
ECS・Nomad のいずれも足りない機能を補う様にアップデートを重ねてきており、徐々に Kubernetes にしか無かった機能が実装されてきています。
そのため、すでに ECS や Nomad で稼働している場合には Kubernetes に移行するメリットは大きくないと思います。
既存のレガシーな環境から移行するべきかという点についても同等なのですが、もし今後もシステムが改修され続けていく状況で移行コストをかけられる様であれば移行も選択肢の一つです。
主軸としては移行しなければ開発効率が上がらないかどうかが判断材料ですね。
(余談)オンプレ上で Kubernetes をやると良いところ
基本的にオンプレ上で Database as a Service や Queue as a Service などを実現するのは運用コストや仕組みづくりが大変です。
Kubernetes の周辺エコシステムを利用することでマネージドサービスを Kubernetes 上で展開することも可能になってきています(mysql-operator、Vitess、NATS など)。
そのため、オンプレ上での Kubernetes にはプライベートクラウドの充実という可能性も感じています。
まとめ
技術選定は組織ごとに好みがあると思うので、あくまでも個人の見解です。
何を選択するにせよ、様々な情報を元に適切に判断すれば良いと思います。
雰囲気で曲解されて Kubernetes is difficult とならないよう、あくまで Kubernetes の苦手意識がなくなるためだけに、一意見として書いてみました。
まとめのまとめ(心の声)
(Kubernetes、いいよ。)
追記 (4/3 15:00)
何度も言いますが、どの環境を使っても良いと思います。コードを書いたら良い感じにしてくれるのが目的です。PaaS でも ECS でも Kubernetes でもアプリケーション開発者からしたらなんでも良いでしょう。
Kubernetes も頑張って CI/CD 整備やマニフェストを書く人がいることによって PaaS の様にして利用しています。
Kubernetes は本当に素の Platform なので、ちゃんとした CI/CD がないとアプリケーション開発に集中できる環境を提供するという目的は達成できません。そのため、あくまでもインフラや SRE にある程度知見のあるメンバーは必要でしょう。
環境を整備すると PaaS も Kubernetes も Nomad も ECS もいちアプリケーション開発者からすると透過的なのが良い形だと思います。
正直単純にオーケストレータを利用する範囲であれば、その学習コストよりもその周辺の考えなきゃいけないこの方が辛いです。
また、どのオーケストレータを選択しても従来の VM で環境を作った時にはいずれも近しい程度の学習コストはかかると思っていた方が良いです。
さくらインターネット研究所 に 客員研究員 としてジョインしました。
こんにちは。amsy810です。
春といえば新しいことを始める時期ですね。
4/1 より さくらインターネット研究所 さんに 客員研究員 としてジョインしました。
新しい経験もしてみたいと思い下記のようなツイートをしたところ、ありがたいことにお誘いを頂いたため新しい挑戦を始めることになりました。
せっかく Portfolio 作ったのと、新しいことを初めてみたくなったので、副業等を探しはじめてみました。
— MasayaAoyama(青山 真也) (@amsy810) 2019年2月12日
(もしスキルセット的にお手伝いできることがあればご連絡ください。)https://t.co/pookSVvJX4 https://t.co/u629B3VP1r
まつもとりーさんからDMで連絡があったのですが、予想外なお話だったので最初は驚きました。 普段からまつもとりーさんのブログなどはウォッチしていたので、お話をいただいた時点で面白そうだなというのは明白でした。
ご存知の方も多いかと思いますが、さくらインターネット研究所さんでは「超個体型データセンター」についての研究を行なっております。 私もこの辺りのお話に携わらせていただく予定です。

詳しくは所長の鷲北さんがまとめています。他にもまつもとりーさんや 研究所のみなさま がまとめた記事もたくさんあるので、探してみてください。(エキスパートのみなさまとお仕事をするのは緊張します。)
数年後に期待されるであろう技術を考えることや、大規模なクラウド事業者の向かう方向性に触れられるのは楽しみです。 最近では "Cloud Native" が広まってきましたが、次のプラットフォームになるようなコアコンセプトなどを考えていけたらと思っております。
また、さくらインターネットさんも CNCF(Cloud Native Computing Foundation)にシルバーメンバーとして参加しています。
再びですが、 CyberAgent を退職するわけではありません。 しっかりとメリハリをつけて本業も頑張りつつ、新しい経験を通じて CA でも引き続き頑張ります。
クリエーションラインに 技術アドバイザー としてジョインしました。
こんにちは。amsy810です。
春といえば新しいことを始める時期ですね。
3/18 より クリエーションラインさんに 技術アドバイザー としてジョインしました。

今とは異なる要件で新しい経験もしてみたいと思い下記のようなツイートをしたところ、ありがたいことにお誘いを頂いたため新しい挑戦を始めることになりました。
主に Kubernetes やコンテナ関連のお仕事をさせていただく予定です。
せっかく Portfolio 作ったのと、新しいことを初めてみたくなったので、副業等を探しはじめてみました。
— MasayaAoyama(青山 真也) (@amsy810) 2019年2月12日
(もしスキルセット的にお手伝いできることがあればご連絡ください。)https://t.co/pookSVvJX4 https://t.co/u629B3VP1r
私自身、技術が好きでこの業界に入ってきたほどなので、色々なことが楽しみです。
クリエーションラインさんは CNCF が提供する 日本で最初の KCSP (Kubernetes Certified Service Providers) で、CNCF 公式のKubernetesトレーニングの提供を含む、Kubernetesやコンテナ関連の事業を展開しています。
具体的な内容についてお話しできないことも多々ありますが、普段中々経験できない業界だったりするので、とても良い経験ができそうだなとワクワクしています。
なお、CyberAgent を退職するわけではありません。
しっかりとメリハリをつけて本業も頑張りつつ、新しい考え方を学んで CA でも引き続き頑張ります。
なお、新しいことを始める話には続きがあり…数日後にまたご報告させていただきます。